 ACME SMART PUBLICATION
ACME SMART PUBLICATION
structure of DNA
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
The DNA
DNA is a long polymer of deoxyribonucleotides.
The length of DNA is usually defined as number of nucleotides or a pair of nucelotide referred to as base pairs present in it.
This also is the characteristic of an organism.
Few examples are sited below :

Chemical structure of DNA polynucleotide :
The basic unit of DNA is a nucleotide which has three components -a nitrogenous base, a pentose sugar (deoxyribose), and a phosphate group.Chemical structure of DNA polynucleotide :
There are two types of nitrogenous bases - Purines (Adenine and Guanine), and Pyrimidines (Cytosine and Thymine).
Cytosine is common for both DNA and RNA and Thymine is present in DNA.
Uracil is present in RNA at the place of Thymine.
A nitrogenous base is linked to the pentose sugar through a N-glycosidic linkage to form a nucleoside, such as adenosine or deoxyadenosine, guanosine or deoxyguanosine, cytidine or deoxycytidine and deoxythymidine.
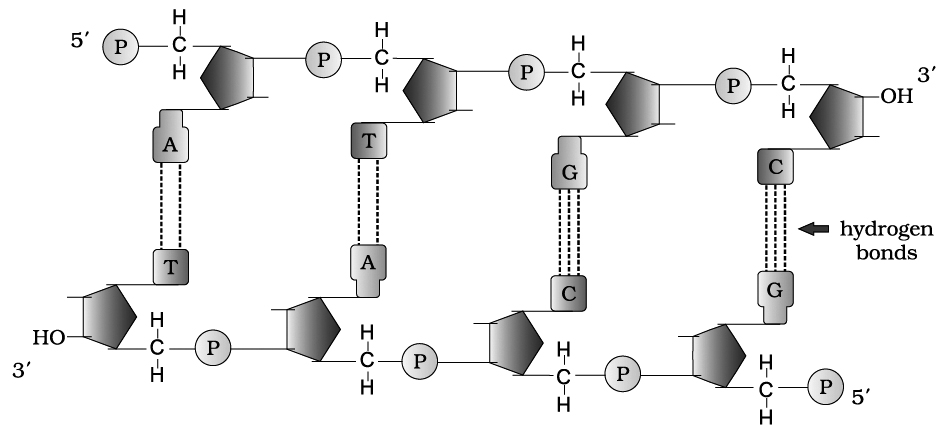
When a phosphate group is linked to 5'-OH of a nucleoside through phosphoester linkage, a corresponding nucleotide (or deoxynucleotide depending upon the type of sugar present) is formed.
Two nucleotides are linked through 3'-5' phosphodiester linkage to form a dinucleotide.
More nucleotides can be joined in such a manner to form a polynucleotide chain.
A polymer thus formed, has a free phosphate moiety at 5'-end of sugar, which is referred to as 5'-end of polynucleotide chain.
Similarly, at the other end of the polymer the sugar has a free 3'-OH group which is referred to as 3'-end of the polynucleotide chain.
The backbone in a polynucleotide chain is formed due to sugar and phosphates (phosphodiester bond) nitrogenous bases linked to sugar moiet projects from the backbone.
In RNA, every nucleotide residue has an additional -OH group present at 2' -position in the ribose.
Also, in RNA the uracil is found at the place of thymine (S-methyl uracil, another chemical name for thymine).
In 1953, James Watson and Francis Crick based on the X-ray diffraction data produced by Maurice Wilkins and Rosalind Franklin, proposed Double Helix model for the structure of DNA.
One of the hallmarks of their proposition was base pairing between the two strands of polynucleotide chain.
However, this proposition was also based on the observation of Erwin Chargaff –that for a double stranded DNA, the ratios between Adenine and Thymine and Guanine and Cytosine are constant and equal.
Chargaff (1950) made observations on the bases and other contents of DNA. These observations or generalizations are called Chargaff's rules.
(i) Purine and pyrimidine base pairs are in equal amount, i.e., adenine + guanine = thymine + cytosine.
(ii) Molar amount of purine (adenine) is always equal to the molar amount of pyrimidine (thymine). Similarly, guanine is equalled by cytosine.
(iii) Sugar deoxyribose and phosphate occur in equimolar proportions.
(iv) The ratio of A + T/G + C is constant for a species (Base ratio, e.g., 1.52 for human and 0.93 for E.coli.
The base pairing is a very unique property of the polynucleotide chains.
They are said to be complementary to each other, and therefore if the sequence of bases in one strand is known then the sequence in other strand can be predicted.
Thus, if one DNA strand has A, the other would have T and if one has G, the other, would have C.
Therefore, if the base sequence of one strand is CAT TAG GAC, the base sequence of other strand would be GTA ATC CTG.
Hence, the two polynucleotide strands are called complementary to one another.
Also, if each strand from a DNA or parental DNA acts as a template for synthesis of a new strand, the two double stranded DNA or daughter DNA produced would be identical to the parental DNA molecule.
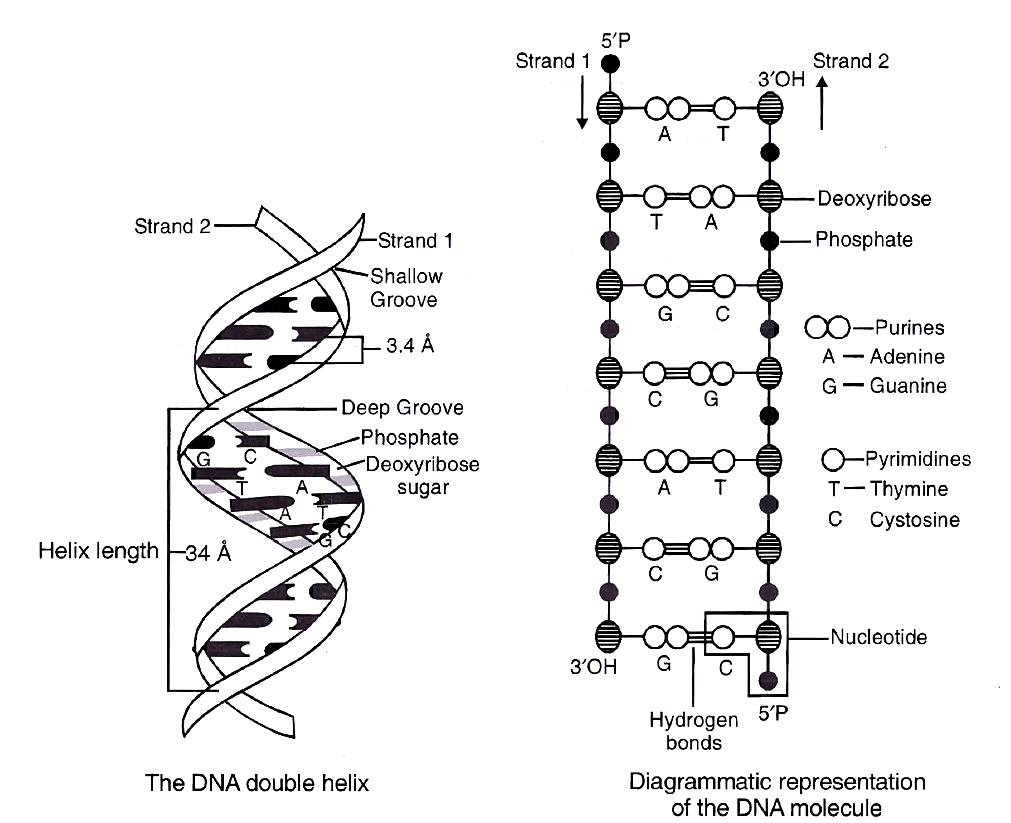
Salient features of DNA Double Helix
(i) It is made of two polynucleotide chains, where the backbone is constituted by sugar-phosphate, and the bases project inside.
(ii) The two chains have anti-parallel polarity. It means, if one chain has the polarity 5P 3OH, the other has 3OH 5P.
(iii) The bases in two strands are paired through hydrogen bond (H-bonds), forming base pairs(bp). Adenine forms two hydrogen bonds with Thymine from opposite strand and vice-versa. Guanine is bonded with Cytosine with three H-bonds. As a result, always a purine comes opposite to a pyrimidine. This generates approximately uniform distance between the two strands of the helix.
(iv) The plane of one base pair stacks over the other in double helix. This, in addition to H-bonds, confers stability to the helical structure.
(v) The two chains are coiled in a right-handed fashion. The pitch of the helix is 3.4 nm and there are roughly 10 bp in each turn. Consequently, the distance between base pairs in a helix is approximately equal to 0.34 nm. It is because of specific base pairing with a purine lying opposite to pyrimidine which makes two chains 2 nm thick.
Concept Builder
Types of DNA and their comparison
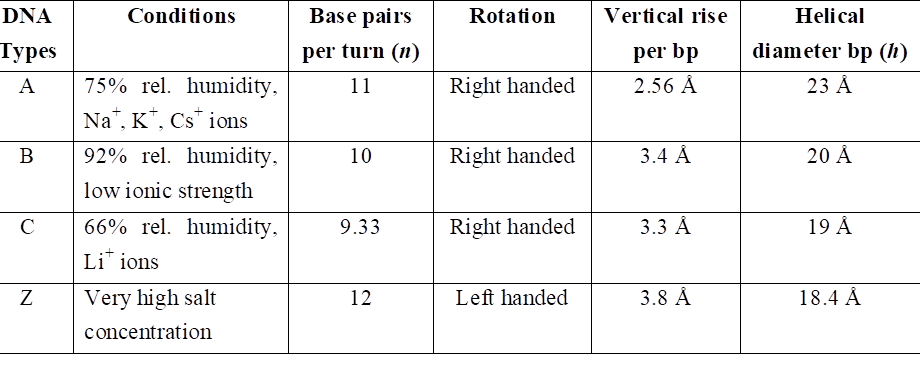
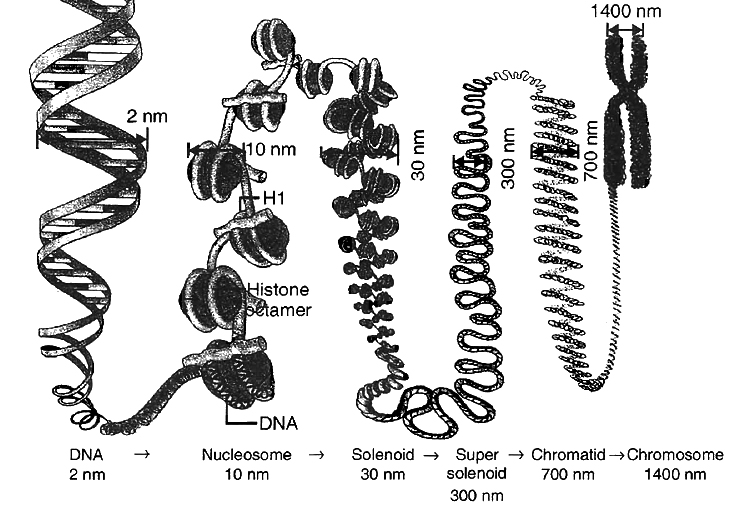
PACKAGING OF DNA HELIX
The average distance between two adjacent base pairs is 0.34 nm (0.34 × 10–9 m or 3.4 Å).
Length of DNA for a human diploid cell is 6.6 × 109 bp × 0.34 × 10–9 m/bp = 2.2 m.
This length is far greater than the dimension of a typical nucleus (approximately 10–6 m).
The number of base pairs in Escherichia coli is 4.6 × 106. The total length is 1.36 mm.
The long sized DNA is accommodated in small area (about 1 µm in E. coli) only through packing or compaction.
DNA is acidic due to presence of large number of phosphate group.
Compaction occurs by folding and attachment of DNA with basic proteins, polyamine in prokaryotes and histone in eukaryotes.
DNA packaging in Prokaryotes :
DNA is found in cytoplasm in supercoiled state.
The coils are maintained by non histone basic protein like polyamines.
RNA may also be involved. This compact structure of DNA is called nucleoid or genophore.
DNA packaging in Eukaryotes :
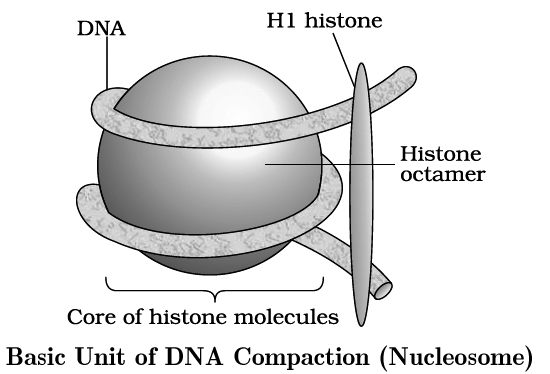
It is carried out with the help of lysine and ariginine rich basic proteins called histones.
The unit of compaction is called nucleosome.
There are five types of histone proteins H1, H2A, H2B, H3 and H4.
Four of them occur in pairs to produce histone octamer (2 copies of each -H2A, H2B, H3 and H4), called nu body or core of nucleosome.
Their positively charged ends are directed outside.
They attract negatively charged strands of DNA.
About 200 bp of DNA is wrapped over nu body to complete about 1¾ turns.
This forms a nucleosome of size 110 × 60 Å (11 × 6 nm).
DNA present between two adjacent nucleosome is called linker DNA.
It is attached to H1 histone protein.
Length of linker DNA varies from species to species.
Nucleosome chain gives a beads on string appearance under electron microscope.
The nucleosomes further coils to form solenoid.
It has diameter of 30 nm as found in chromatin.
The beads-on-string structure in chromatin is packaged to form chromatin fibres that are further coiled and condensed at metaphase stage of cell division to form chromosomes.
The packaging at higher level requires additional set of proteins (acidic) that collectively are referred to as non-histone chromosomal (NHC) proteins.
Non-Histone Chromosomal proteins are of three types:
(i) Scaffold or Structural NHC protein.
(ii) Functional NHC protein, e.g., DNA polymerase, RNA polymerase.
(iii) Regulatory NHC protein, e.g., HMG (High mobility group proteins that controls gene expression).
In a typical nucleus, some region of chromatin are loosely packed (and stains light) and are referred to as euchromatin.
The chromatin that is more densely packed and stains dark is called as heterochromatin, specifically euchromatin is said to be transcriptionally active and heterochromatin is transcriptionally inactive.
Chemical Composition of Chromosome
A chromosome consists of following chemical compositions:
(a) DNA 40%
(b) RNA 1.2%
(c) Histone protein 50%
(d) Acidic proteins 8.5%
(e) Lipid traces
(f) Ca+2, Mg+2, Fe+2 traces
the search of genetic material
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
THE SEARCH FOR GENETIC MATERIAL
The experiments given below prove that DNA is the genetic material.
(I) Evidence from bacterial transformation.
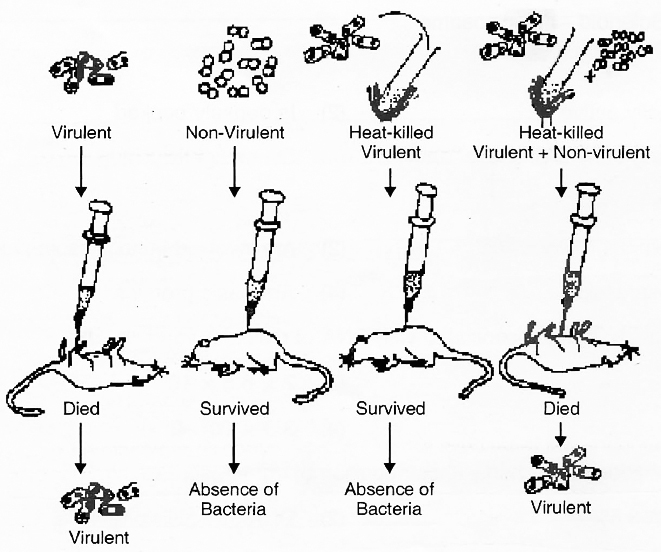
The transformation experiments, conducted by Frederick Griffith in 1928, are of great importance in establishing the nature of genetic material.
He used two strains of bacterium Diplococcus or Streptococcus pneumoniae or Pneumococcus i.e., S-III and R-II.
(1) Smooth (S) or capsulated type which have a mucous coat and produce shiny colonies. These bacteria are virulent and cause pneumonia.
(2) Rough (R) or non-capsulated type in which mucous coat is absent and produce rough colonies. These bacteria are nonvirulent and do not cause pneumonia.
The experiment can be described in following four steps :
(a) Smooth type bacteria were injected into mice. The mice died as a result of pneumonia caused by bacteria.
S strain Injected into mice Mice died
(b) Rough type bacteria were injected into mice. The mice lived and pneumonia did not occur.
R strain Injected into mice Mice lived
(c) Smooth type bacteria which normally cause disease were heat killed and then injected into the mice. The mice lived and pneumonia was not caused.
S strain (heat killed) Injected into mice Mice lived
(d) Rough type bacteria (living) and smooth type heat-killed bacteria (both known not to cause disease) were injected together into mice. The mice died due to pneumonia and virulent smooth type living bacteria could also be recovered from their dead bodies.
S strain (heat killed) + R strain (living) Injected into mice Mice died
He concluded from fourth step of the experiment that some rough bacteria (nonvirulent) were transformed into smooth type of bacteria (virulent).
This occurred perhaps due to absorption of some transforming substance by rough type bacteria from heat killed smooth type bacteria.
This transforming substance from smooth type bacteria caused the synthesis of capsule which resulted in production of pneumonia and death of mice.
Therefore, transforming principle appears to control genetic characters (for example, capsule as in this case). However, the biochemical nature of genetic material was not defined from his experiments.
Biochemical Characterisation of Transforming Principle
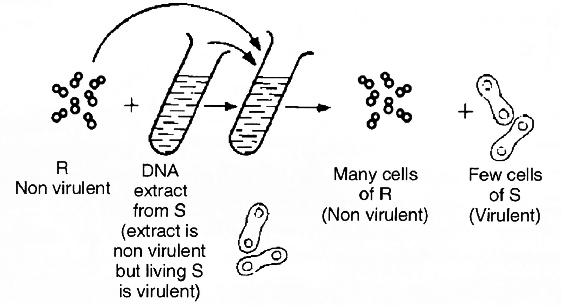
Later, Avery, Macleod and McCarty (1944) repeated the experiment in-vitro to identify the biochemical nature of transforming substance. They proved that this substance is DNA.
Pneumococcus bacteria cause disease when capsule is present. Capsule production is under genetic control.
In the experiments, rough type bacteria (non-capsulated and non-virulent) were grown in a culture medium to which DNA extract from smooth type bacteria (capsulated and virulent) was added.
Later, the culture showed the presence of smooth type bacteria also in addition to rough type.
This is possible only if DNA of smooth type was absorbed by rough type bacteria which developed capsule and became virulent.
This process of transfer of characters of one bacterium to another by taking up DNA from solution is called transformation.
When DNA extract was treated with DNase (an enzyme which destroys DNA), transformation did not occur.
The transformation occurs when proteases and RNases were used. This clearly shows that DNA is the genetic material.
(II) Evidence from experiments with bacteriophage.
T2 bacteriophage is a virus that infects bacterium Escherichia coli and multiplies inside it.
T2 phage is made up of DNA and protein coat.
Thus, it is the most suitable material to determine whether DNA or protein contains information for the production of new virus (phage) particles.
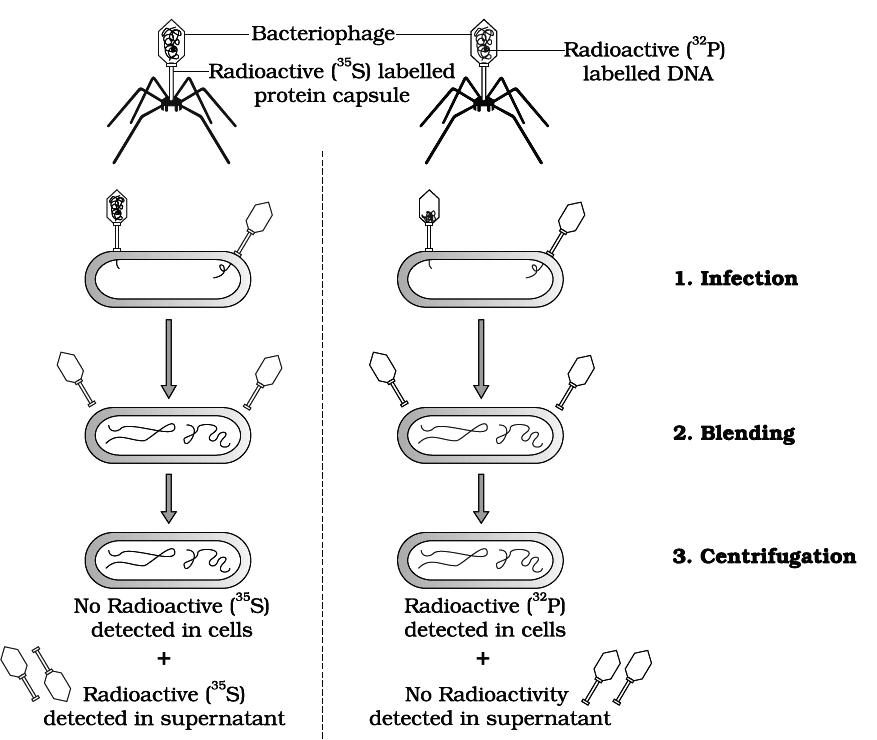
Hershey and Chase (1952) demonstrated that only DNA of the phage enters the bacterial cell and, therefore, contains necessary genetic information for the assembly of new phage particle.
The functions of DNA and proteins could be found out by labelling them with radioactive tracers.
DNA contains phosphorus but not sulphur.
Therefore, phage DNA was labelled with P32 by growing bacteria infected with phages in culture medium containing 32P.
Similarly, protein of phage contains sulphur but no phosphorus.
Thus, the phage protein coat was labelled with S35 by growing bacteria infected with phages in another culture medium containing 35S.
After the formation of labelled phages. Three steps were followed, i.e., infection, blending, centrifugation.
1. Infection: Both types of labelled phages were allowed to infect normally cultured bacteria in separate experiments.
2. Blending: These bacterial cells were agitated in a blender to break the contact between virus and bacteria.
3. Centrifugation: The virus particles were separated from the bacteria by spinning them in a centrifuge.
After the centrifugation the bacterial cells showed the presence of radioactive DNA labelled with P32 while radioactive protein labelled with S35 appeared on the outside of bacteria cells (i.e., in the medium).
Labelled DNA was also found in the next generation of phage.
This clearly showed that only DNA enters the bacterial host and not the protein.
DNA, therefore, is the infective part of virus and also carries all the genetic information.
This provided the unequivocal proof that DNA is the genetic material.
that DNA is genetic material or DNA is infective part of virus
Properties of Genetic Material :
Following are the properties and functions which should be fulfilled by a substance if it is to qualify as genetic material.
(1) It should chemically and structurally be stable.
(2) The genetic material should be able to transmit faithfully to the next generation, as Mendelian characters.
(3) The genetic material should also be capable of undergoing mutations.
(4) The genetic material should be able to generate its own kind (replication).
This can be concluded after examining the above written qualities, that DNA being more stable is preferred as genetic material, as
(a) Free 2OH of RNA makes it more labile and easily degradable. Therefore, DNA in comparison is more stable.
(b) Presence of thymine at the place of uracil also confers additional stability to DNA.
(c) RNA being unstable, mutates at a faster rate.
RNA world
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
RNA World
RNA was the first genetic material.
There are evidences to suggest that essential life processes, such as metabolism, translation, splicing, etc. evolved around RNA.
RNA used to act as a genetic material as well as a catalyst.
There are some important biochemical reactions in systems that are catalyzed by RNA catalysts and not by proteinaceous enzymes (e.g., splicing).
RNA being a catalyst was reactive and hence unstable .
Therefore, DNA has evolved from RNA with chemical modifications that make it more stable.
DNA being double stranded and having complementary strand further resists changes by evolving a process of repair.
RNA is an adapter, structural molecule and in some cases catalytic.
Thus, RNA is better material for transmission of information.
Dna replication
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
REPLICATION OF DNA
The Watson-Crick model of DNA immediately suggested that the two strands of DNA would separate.
Each separated or parent strand serves as a template (model or guide) for the formation of a new but complementary strand.
Thus, the new or daughter DNA molecules formed would be made of one old or parental strand and another newly formed complementary strand.
This method of formation of new daughter DNA molecules is called semi-conservative method of replication.
The following experiment suggests that DNA replication is semi-conservative.
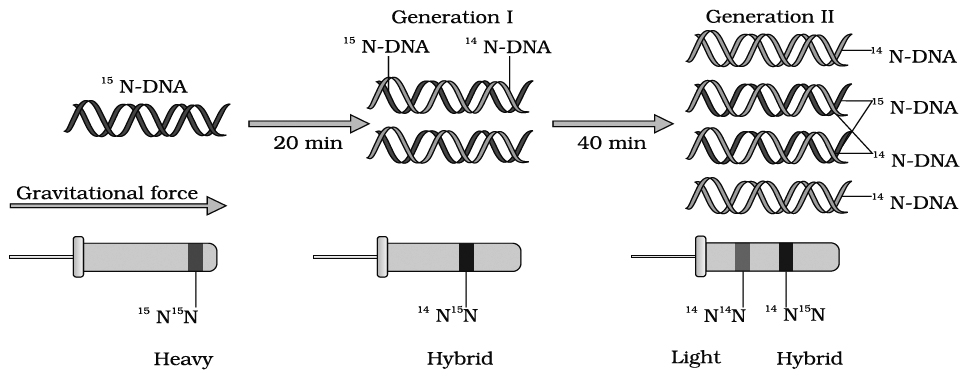
Messelson and Stahl (1958) conducted experiments using heavy nitrogen (15N) to determine whether the concept of semi-conservative replication is correct.
They used Cesium chloride (CsCl) gradient centrifugation technique for this purpose.
A dense solution of CsCl, on centrifugation, forms density gradient-bands of a solution of lower density at the top that increases gradually towards bottom with highest density.
If DNAs of different densities are mixed with CsCl solution, these would separate from one another and would form a definite density band in the gradient along with CsCl solution.
Messelson and Stahl created DNA molecules of different densities by using normal nitrogen 14N and its heavy isotope 15N.
For this purpose, Escherichia coli was grown in 15NH4Cl containing culture medium for many generations, so that bacterial DNA become completely heavy.
This non-radioactive or heavy DNA (incorporating 15N) had more density than DNA with normal nitrogen (14N).
The bacteria were then transferred to culture medium containing only normal nitrogen (14NH4Cl). The change in density was observed by taking DNA samples periodically.
Messelson and Stahl's Experiment
If DNA replicates semi-conservatively, then each heavy (15N) DNA strands should separate and each separated strand should acquire a light (14N) partner after one round of replication.
This should be a hybrid DNA made of two strands, i.e., 14N–15N.
Meselson and Stahl observed that such DNA was actually half dense indicating the presence of hybrid DNA molecules.
After second round of replication there would be four DNA molecules.
Of these, two molecules would be hybrid (14N–15N) showing half density as earlier and the remaining two molecules would be made of light strands (14N–14N) Thus, after second generation, the same half dense band (14N–15N) was seen but the density of light bands (14N–14N) increased.
Messelson and Stahl's work as such provided confirmation of Watson-Crick model of DNA and its semi-conservative replication.
Taylor proved semiconservative mode of chromosome replication in eukaryotes using tritiated thymidine in the root of Vicia faba (faba beans).
Cairns proved semiconservative mode of replication in E. coli by using tritiated thymidine (H3–tdR) in autoradiography experiment.
He proposed -model for replication in circular DNA.
Mechanism of DNA Replication
DNA replication involves following four major steps:
(1) Initiation of DNA replication
(2) Unwinding of helix
(3) Formation of primer strand
(4) Elongation of new strand
1. Initiation of replication.
Replication of DNA always begins at a definite site called origin of replication.
Prokaryotes have single origin of replication.
It is called ori-c in E.coli.
On the other hand, eukaryotes have several thousand origins of replication.
2. Unwinding of helix.
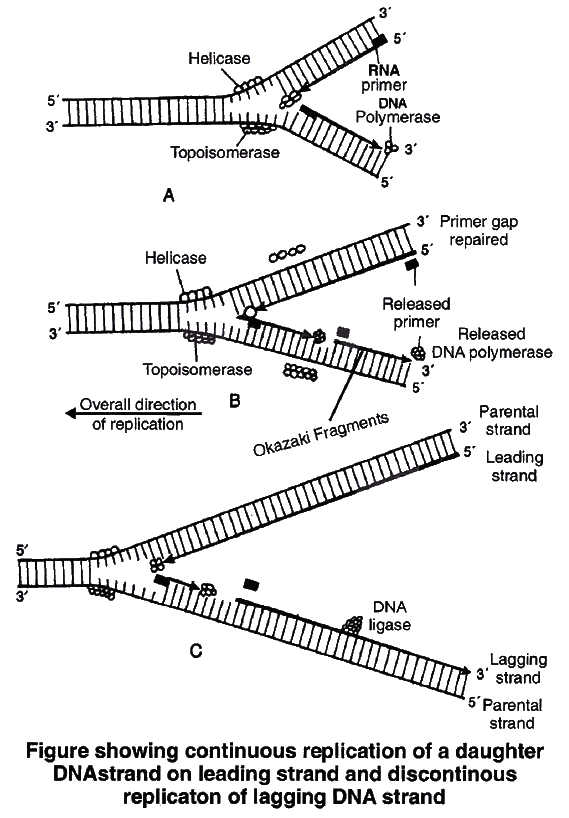
DNA replication requires that a double helical parental molecule is unwound so that its internal bases are available to the replication enzymes.
Unwinding is brought about by enzyme helicase which is ATP dependent.
Unwinding of DNA molecule into two strands results in the formation of Y-shaped structure, called replication fork.
These exposed single strands are stabilised by a protein known as Single-strand binding protein (SSB).
Due to unwinding, a supercoiling develops on the end of DNA opposite to replicating fork.
This tension is released by enzyme topoisomerase.
3. Formation of primer strand.
A new strand is to be synthesized opposite to the parental strands DNA polymerase III is the true replicase in E. coli, which is incapable of initiating DNA synthesis, i.e., it is unable to deposit the first nucleotide in a daughter (new) strand without the Primer.
Another enzyme, known as primase, strand synthesizes a short primer strand of RNA.
The primer strand then serves as a stepping stone (to start errorless replication).
Once the initiation of DNA synthesis is completed, this primer RNA strand is then removed enzymatically.
4. Elongation of new strand.
Once the primer strand is formed, DNA replication occurs in 53 direction, i.e., during synthesis of a new strand, deoxyribonucleoside triphosphates (dATP, dGTP, dTTP, dCTP) are added only to the free 3OH end.
Thus, the nucleotide at 3 end is always the most recently added nucleotide to the chain.
As the DNA replication proceeds on the two parental strands, synthesis of daughter or new strand occurs continuously along the parent 3'5' strand.
It is now known as leading daughter strand.
Synthesis of another daughter strand along the other parental strand, however, takes place in the form of short pieces.
This is called lagging daughter strand. These short pieces of DNA are known as Okazaki fragments, these segments are about 1,000-2,000 nucleotides long in prokaryotes.
Hense, DNA replication is semidiscontinuous. Discontinuous pieces of the lagging strand are joined together by the enzyme DNA ligase (after removal of primer) to form continuous daughter strand.
Thus two DNA molecules are now formed from one molecule.
Each of these daughter DNA molecules is made of two strands, of which one is old (parental) and other one is new or complementary strand.
DNA polymerase is the most important enzyme of DNA replication.
DNA polymerases are of three types i.e. DNA polymerase I, II and III in prokaryotes.

DNA polymerase II & III have only 3' 5' exonuclease activity.
Kornberg (1956), succeeded in demonstrating the in vitro synthesis of DNA molecule using a single strand of DNA as a template.
He extracted and purified an enzyme from E. coli which was capable of linking free DNA nucleotides, in presence of ATP as an energy source, to form complementary strand.
He called it DNA polymerase. DNA polymerase-I is called Kornberg enzyme.
In eukaryotes DNA polymerases are of 5 type these are DNA polymerase , , , and .
In eukaryotes, the replication of DNA takes place at s-phase of the cell cycle. The replication of DNA and cell division cycle should be highly co-ordinated. A failure in cell division after DNA replication result into polyploidy (achromosomal anomaly).
STRUCTURE OF RNA (Ribose Nucleic Acid)
RNA or ribonucleic acid is present in all the living cells. It is laevo rotatory and is responsible for learning and memory. It is found in the cytoplasm as well as nucleus. Description of types and structure of RNA is given below.
Types of RNA
In bacteria, there are three major types of RNAs: mRNA (messenger RNA), tRNA (transfer RNA), and rRNA (ribosomal RNA).
All three RNAs are needed to synthesise a protein in a cell.
The mRNA provides the template, tRNA brings aminoacids and reads the genetic code, and rRNAs play structural and catalytic role during translation.
RNA is generally involve in protein synthesis but in majority of plant viruses, it serves as a genetic material. Therefore, there are two major types of RNA-(A) genetic RNA and (B) non-genetic RNA.
(A) Genetic RNA -
Fraenkel-Conrat showed that RNA present in TMV (Tobacco Mosaic Virus) is a genetic material. Since then, it is established that RNA acts as a genetic material in most plant viruses.
(B) Non-genetic RNA.
This type of RNA is commonly present in cells where DNA is genetic material. Non-genetic RNA is synthesized on DNA template. It is of following three major types:
(a) Messenger RNA (mRNA).
It was reported by Jacob and Monad.
It carries genetic information present in DNA, so is called working copy.
mRNA constitutes about 3-5% of the total RNA present in the cell.
The molecular weight varies from 25,000 to 1,00,000.
It is about 300 nucleotide long at minimum.
Structure of prokaryotic m-RNA. It is polycistronic in nature i.e., several cistrons (functional part of DNA) form a single m-RNA. Thus, each m-RNA has a message to produce several polypeptides. Average life is 2 minutes.
At 5' end near initiation codon a sequence of fixed bases is found called Shine Dalgarno(SD) sequence (5'AGGAGGU3'). It helps in correct binding of ribosomal subunit (30 S) on it.
Structure of eukaryotic m-RNA. It is monocistronic in nature and has a message to produce on polypeptide only. They are metabolically stable and their life varies from few hours to days.

UTR (Untranslated region). They are sequences of RNA before start or initiation codon and after stop or termination codon. They are not translated. They are transcribed as part of same transcript as the coding region. Such UTRs provide stability to m-RNA and also increase translational efficiency.
(b) Ribosomal RNA (rRNA). It was reported by Kuntz. It is most stable type of RNA and is a constituent of ribosomes. It forms about 80% of the total cellular RNA.
In eukaryotes, 4 types of rRNA's found are 28 S, 18 S, 5.8 S and 5 S whereas, in prokaryotes three types of rRNA's found are 23 S, 16 S and 5 S. It is synthesised by genes present on DNA of several chromosomes found within a region known as nucleolar organiser.
(c) Transfer RNA (tRNA). The existence of tRNA was postulated by Crick. It is also known as soluble RNA (sRNA). These are the smallest molecules which carry amino acids to the site of protein synthesis. These constitute about 15% of the total cellular RNA.
It acts as an intermediate molecule between triplet code of mRNA and amino acid sequence of polypeptide chain. All tRNA's have almost same basic structure. There are over 60 types of tRNA.
Structure of t-RNA
Clover leaf model of tRNA is a 2-dimensional model suggested by Holley et.al. tRNA molecule appears like a clover leaf, being folded with three or more double helical regions (stem), having loops also. The three dimensional structure of the tRNA was proposed to be inverted L-shaped by Kim and Klug.
All tRNA molecules commonly have a guanine residue at its 5' terminal end. At its 3' end, unpaired – CCA sequence is present. Amino acid gets attached at this end only. The number of nucleotide varies from 77 (tRNAalanine) to 207 (tRNAtyrosine).
There are three loops in t-RNA
(i) Amino acyl synthetase binding loop, also called DHU loop.
(ii) Ribosomal binding loop with 7 unpaired bases. It is also called TC loop.
(iii) Anticodon loop with 7 unpaired bases. Out of the 7 bases in anticodon loop, 3 bases acts as anticodon for a particular triplet codon present on mRNA.
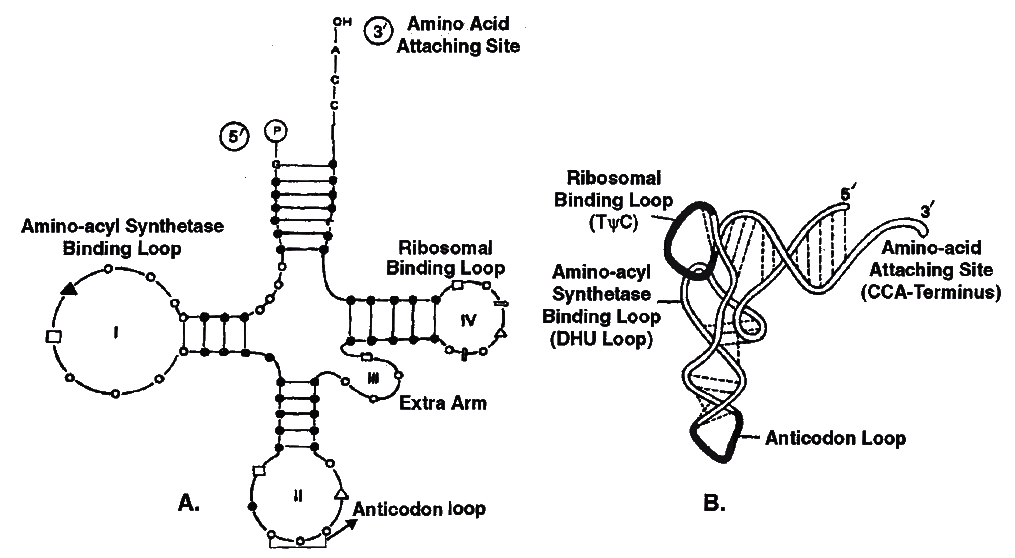
Structure of tRNA
A. Clover leaf model to show basic plan of tRNA secondary structure or 2D structure
B. Three Dimensional Structure showing L-shaped configuration
GENE EXPRESSION
DNA, being the genetic material, carries all the informations necessary to programme the functions of a cell by controlling the synthesis of enzymes or proteins.
Beadle and Tatum put forward a theory-one gene one enzyme in support of the earlier hypothesis that enzymes are proteinaceous in nature and each is produced by a single gene.
They conducted experiments on the nutritional strains of pink mould, Neurospora crassa.
This fungus grows on simple nutrient medium and has the ability to synthesize all its cellular components.
Such an organism is called prototroph.
An organism that is unable to synthesize a particular cellular metabolite, such as an amino acid or coenzyme is called auxotroph.
Beadle and Tatum produced arginine (an amino acid) auxotrophs (mutants of Neurospora unable to synthesize arginine) by giving X-rays treatment to the cells. Arginine synthesis passes through the following path

They found that any step of this metabolic chain could be blocked by a mutation in a specific enzyme catalyzing the reaction, each enzyme representing a different gene product.
Thus, Beadle and Tatum reached a conclusion that each gene functions to produce a single enzyme.
Some proteins, e.g., haemoglobin and other quaternary proteins are made up of two or more than two polypeptide chains. After it, the 'one gene one enzyme' theory was modified into one gene one polypeptide hypothesis by Yanofsky. Later Jacobson and Baltimore proposed one mRNA -one polypeptide hypothesis.
Gene and protein : A gene expresses itself by protein synthesis.
When a particular gene is expressed (i.e., controls a function or a reaction), its information is copied into another nucleic acid, i.e., mRNA (messenger RNA) which in turn directs the synthesis of specific proteins.
These concepts form the central dogma of molecular biology. This has been shown by F. Crick in the following diagram.
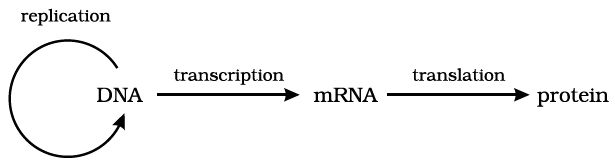
An exception to this one way flow of information was reported in 1970.
H. Temin and D. Baltimore independently discovered reverse transcription in some viruses.
These viruses can code an enzyme reverse transcriptase which can code DNA on RNA template.
This discovery was important in understanding cancer and, hence, these two scientists were awarded Nobel Prize. The modified flow of information now can be shown as below:

 Reverse flow of transcriptional information or Reverse Central Dogma or Teminism
Reverse flow of transcriptional information or Reverse Central Dogma or Teminism
Commoner suggests circular flow of information.
transcription
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
MECHANISM OF PROTEIN SYNTHESIS
The process of protein synthesis consists of two major steps:
(A) Transcription or synthesis of mRNA on DNA
(B) Translation or synthesis of proteins along mRNA
(A) Transcription
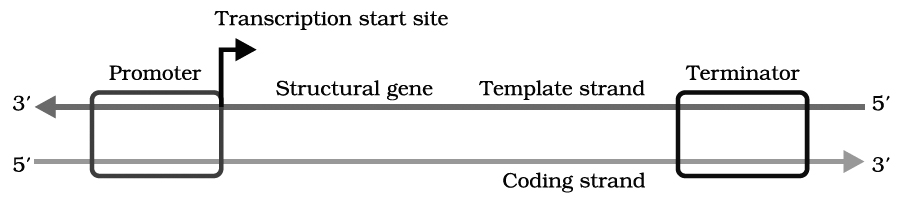
The transfer of genetic information from DNA to mRNA is known as transcription. The segment of DNA that takes part in transcription is called transcription unit. It has three components.
(i) A Promoter
(ii) The Structural gene
(iii) A Terminator
Promoter seguences are present upstream (5' end) of the structural genes of a transcription unit.
The binding sites for RNA polymerase lie within the promoter sequence.
Certain short sequences within the promoter sites are conserved. In prokaryotes, 10 bp upstream from, the start point lies a conserved sequence described as –10 sequence TATAAT or "Pribnow box" and –35 sequence TTGACA as "Recognition sequence".
Schematic structure of a transcription unit
Structural gene is part of that DNA strand which has 3' 5' polarity, as transcription occur in 5' 3' direction. This strand of DNA that direct the synthesis of mRNA is called template strand. The complementary strand is called non-template or coding strand, it is identical in base sequence to RNA transcribed from the gene, only with U in place of T.
Terminator is present at 3' end of coding strand and defines the end of the process of transcription.
Mechanism of transcription
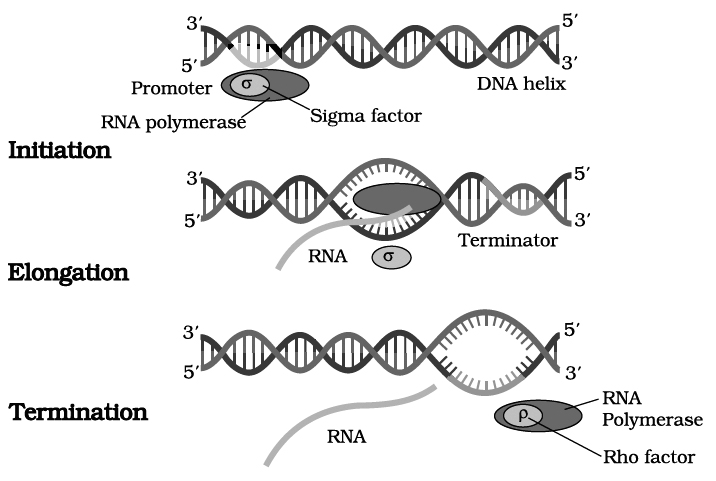
RNA polymerase binds to promoter region of the DNA and the process of transcription begins.
RNA polymerase moves along DNA helix and unwinds it.
One of the two strands of DNA serves as a template for RNA synthesis.
This results in the formation of complementary RNA strand.
It is formed at a rate of about 40 to 50 nucleotides per second.
RNA synthesis comes to a stop when RNA polymerase reaches the terminator sequence.
The transcription enzyme, i.e., RNA polymerase is only of one type in prokaryotes and can transcribe all types of RNAs.
RNA polymerase is a holoenzyme that is represented as (2').
Molecular weight of holoenzyme is 4,50,000.
The enzyme without subunit is referred to as core enzyme.
Though, the core enzyme is capable of transcribing DNA into RNA but transcription starts non specifically at any base on DNA.
It is subunit which confers specificity. Rho factor () is required for termination of transcription.
(a) Sigma Factor () : Binds to the promoter site of DNA and it initiates transcription.
(b) Core Complex : It continues the transcription.
(c) Rho Factor () : It terminates transcription, its molecular weight is 55,000.
Transcription in Eukaryotes
In eukaryotes, the promotor site is recognised by presence of specific nucleotide sequence called TATA box or Hogness box (7 base pair long -TATATAT or TATAAAT) located 20 bp upstream to the start point.
Another sequence is CAAT box present between -70 and -80 bp.
In eukaryotes, the RNA polymerases are of three types, i.e., RNA polymerase I, RNA polymerase II and RNA polymerase III.
Functions of different RNA polymerases in eukaryotes are given below:
(i) RNA polymerase-I 5.8 S, 18 S, 28 S rRNA synthesis
(ii) RNA polymerase-II Hn RNA (heterogenous nuclear RNA), mRNA synthesis
(iii) RNA polymerase-III tRNA, Sc RNA (small cytoplasmic RNA), 5S rRNA and Sn RNA (small nuclear RNA) synthesis.
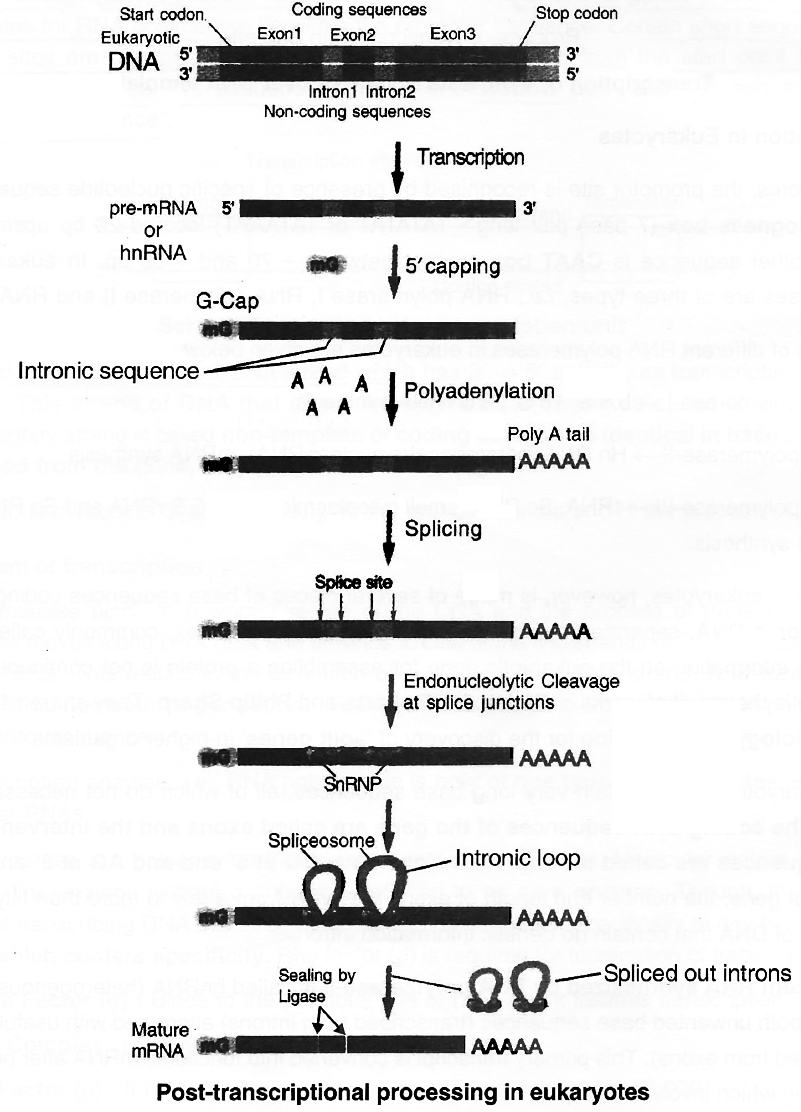
The gene in eukaryotes, however, is made of several pieces of base sequences coding for amino acids called exonic DNA, separated by stretches of non-coding sequences, commonly called intronic DNA.
Thus, the information on the eukaryotic gene for assembling a protein is not continuous but split.
This discovery is the result of works of Richard J. Roberts and Philip Sharp.
They shared 1993 Nobel Prize for Physiology and Medicine for the discovery of 'split genes' in higher organisms.
Most eukaryotic genes contain very long base sequences, all of which do not necessarily form mature mRNA.
The coding DNA sequences of the gene are called exons and the intervening non-coding DNA sequences are called introns.
All introns have GU at 5' end and AG at 3' end. Depending on the size of gene, the number and length of exons may vary from a few to more than fifty, alternating with stretches of DNA that contain no genetic information introns.
The nascent RNA synthesized by RNA polymerase-II is called hnRNA (heterogenous nuclear RNA).
It contains both unwanted base sequences (transcribed from introns) alternated with useful base sequences (transcribed from exons).
This primary transcript is converted into functional mRNA after post-transcriptional processing which involves 3 steps:
1. Modification of 5' end by Capping: Capping at 5' end occurs rapidly after the start of transcription.
The guanosine methylated at 7th position is added at 5' with the help of enzyme guanyl transferase.
Cap is essential for formation of mRNA-ribosome complex.
Translation is not possible if cap is lacking, because cap is identified by 18 S rRNA of ribosome unit.
2. Polyadenylation at 3' end (Tailing) : Poly (A) is added to 3' end of newly formed hn RNA with the help of enzyme Poly A polymerase. It adds about 200-300 adenyl ate residues.
3. Splicing of hnRNA (Tailoring) : In eukaryotes the coding sequences of RNA (exons) are interrupted by non coding sequences (introns).
Small nuclear RNA (snRNA) + Protein complex called small nuclear ribonucleo protein or SnRNPs (or snurps) play important role in this process.
Here the introns are removed and exons come in one plane.
This process is called splicing through which a mature mRNA is produced.
Normally, mRNA carries the codons of single complete protein molecule (monocistronic mRNA) in eukaryotes, but in prokaryotes, it carries codons from several adjacent DNA cistrons and becomes much longer in size (polycistronic mRNA).
Genetic code
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
Genetic Code
Term was coined by Gamow.
DNA (or RNA) carries all the genetic information.
It is expressed in the form of proteins.
Proteins are made up of 20 different types of essential amino acids.
The information about the number and sequence of these amino acids forming protein is present in DNA and is passed on to mRNA during transcription.
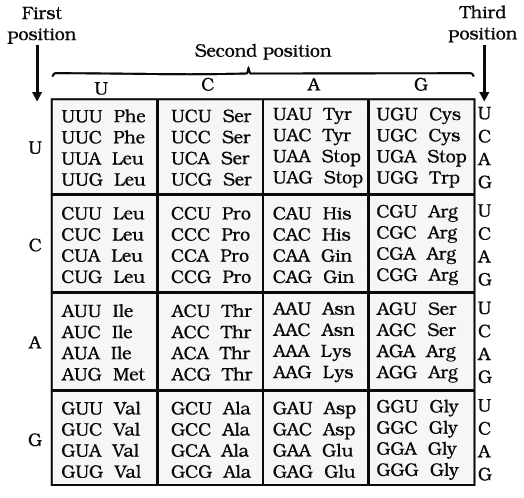
Genetic code is a mRNA sequence containing coded information for one amino acid and consists of three nucleotides (triplet).
Thus, for twenty amino acids, 64 (4 × 4 × 4 or 43 = 64) minimum possible permutations are available.
This important discovery was the result of experiments by Marshall W. Nirenberg and J. Heinrich Matthaei and later by H.G. Khorana. Nirenberg and Khorana shared the 1968 Nobel Prize with R.W. Holley who gave details of tRNA structure. Nirenberg and Mathaei used a synthetic poly (U)RNA and deciphered the code by translating this as polyphenylalanine. Hargobind Khorana, using synthetic DNA, prepared polynucleotide with known repeating sequence, e.g., CUCUCUCUCUCU, it produced only two amino acids, leucine (CUC) and serine (UCU).
Properties of Genetic Code
1. Triplet code. Three adjacent nitrogen bases constitute a codon which specifies the placement of one amino acid in a polypeptide.
2. Start signal. Polypeptide synthesis is signalled by two initiation codons-AUG or rarely GUG. The first or initiating amino acid is methionine. The initiating codon on mRNA for methionine is AUG. Initiating methionine occurs in formylated state in prokaryotes. At other positions methionine is non-formylated. Both these methionines are carried by different tRNAs.
Rarely, GUG also serves as initiation codon. It normally codes for valine but if present at initiating position, it would code for methionine. So, GUG is an ambiguous codon .
3. Stop signal. Polypeptide chain termination is signalled by three termination codons-UAA (ochre), UAG (amber) and UGA (opal). They do not specify any amino acid and were hence called as nonsense codons. Whenever present in mRNA, these bring about termination of polypeptide chain and thus, act as stop signals. Codon UAA, UAG, UGA, AUG, and GUG are also called as punctuation codons.
4. Commaless. The genetic code is continuous and does not possess pauses (meaningless base) after each triplet. If a nucleotide is deleted or added, the whole genetic code will read differently. Thus, a polypeptide having 50 amino acids shall be specified by a linear sequence of 150 nucleotides. If a nucleotide is added or deleted in the middle of this sequence, the amino acids before this will be same but subsequent amino acids will be quite different.
5. Universal code. The genetic code is applicable universally, i.e., a codon specifies the same amino acid from a virus to human being or a tree.
6. Non-overlapping code. Every codon is independent and one codon does not overlap the next codon.
7. Degeneracy of code. Since there are 64 triplet codons and only 20 amino acids, the incorporation of some amino acids must be influenced by more than one codon. Only tryptophan and methionine are specified by single codons. All other amino acids are specified by 2-6 codons. The latter are called degenerate codons.
Wobble Hypothesis
A change in nitrogen base at the third position of a codon does not normally cause any change in the expression of the codon because the codon is mostly read by the first two nitrogen bases (wobble hypothesis of Crick).
The mutation that does not cause any change in the expression of the gene is called silent mutation.
The position of the third nitrogen base in a codon which does not influence the reading of the codon is termed as Wobble position.
It pairs with 1st position in anticodon. It means specificity of codon is determined by first two bases.
Wobbling helps one tRNA to read more than one codon and thus, provides economy in number of tRNA molecules at the time of translation.
Mutations and genetic code :
In a hypothetical mRNA, for example, the codons would normally be translated as follows :
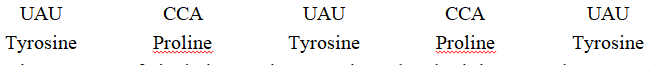
The insertion of single base G between the 3rd and 4th bases produces completely different protein from earlier one.

Similarly, the deletion of single base C at 4th place produces a new chain of amino acids and hence a different protein.

Such mutations are called frame shift mutations.Insertion or deletion of one or two nitrogenous bases changes the reading frame from the point of insertion or deletion.
However, insertion or deletion of three or its multiple bases insert or delete one or multiple codons hence one or multiple amino acids and reading frame remains unaltered from that point onwards.
This form genetic basis of proof that codon is a triplet and it is read in a contiguous manner.
Assignment of mRNA codons to Amino Acids
Translation
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
Translation
It is the mechanism by which the triplet base sequences of m-RNA molecules are converted into a specific sequence of amino acids in a polypeptide-chain. It occurs on ribosomes.
The major steps are:
(a) Activation of amino acids. In the presence of enzyme aminoacyl -tRNA synthetase (E), specific amino acids (AA) bind with ATP
![]()
 (b) Charging of t-RNA. The AA1-AMP-E1 complex formed in first step reacts with a specific tRNA. Thus, amino acid is transferred to tRNA. As a result, the enzyme and AMP are liberate
(b) Charging of t-RNA. The AA1-AMP-E1 complex formed in first step reacts with a specific tRNA. Thus, amino acid is transferred to tRNA. As a result, the enzyme and AMP are liberate
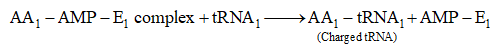
(c) Formation of polypeptide chain. It is completed in three steps.
(i) Chain Initiation. It requires 3 initiation factors in prokaryotes i.e., IF3, IF2, IF1.
9 initiation factors are required in eukaryotes i.e., eIF2, eIF3, eIF1, eIF4A, eIF4B, eIF4C, eIF4D, eIF5, eIF6.
(a) Binding of mRNA with smaller subunit of ribosomes (30S/40S). IF3 is involved in prokaryotes, while eIF2 is involved in eukaryotes. It involves interaction between Shine Delgarno sequence and 3' end of 16 S rRNA in prokaryotes.
(b) Binding of 30S / 40S-mRNA complex with t-RNA. Non-formylated methionine is attached with tRNA in eukaryotes and formylated methionine in prokaryotes. IF2 is involved in prokaryotes and eIF3 in eukaryotes.
![]()
(c) Attachment of larger subunit of ribosomes.
Initiation factors in eukaryotes -eIFl, eIF4.
Initiation factors in prokaryotes -IF1.
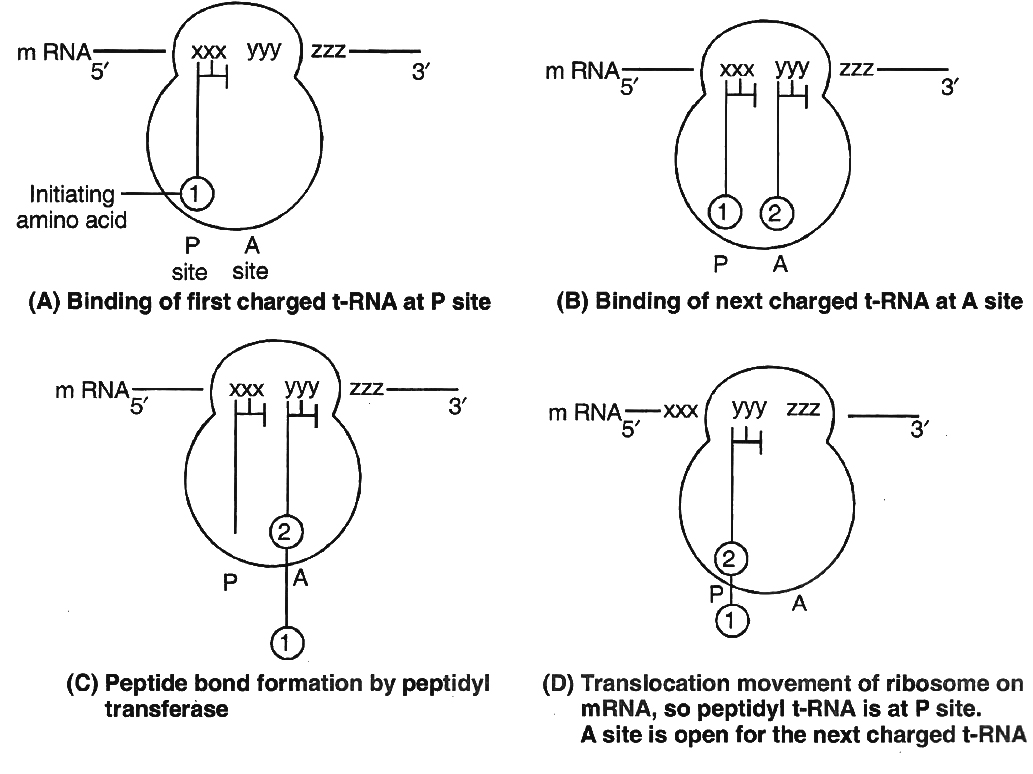
(ii) Chain elongation.
Ribosomes have two sites for binding amino acyl tRNA (i) Amino acyl or A site (acceptor site) (ii) Peptidyl site or P site (donor site).
A second charged tRNA molecule along with its appropriate amino acid approaches the ribosome at A site close to the P site.
Its anticodon binds to complementary codon of mRNA chain.
A peptide bond is formed between COOH group of first amino acid (methionine) and NH2 group of second amino acid.
The formation of peptide bond requires energy and is catalysed by enzyme peptidyl transferase. The initiating formyl methionine or methionine tRNA can bind only with P site.
All other newly coming aminoacyl tRNA bind to A site.
The elongation factor required for prokaryotes are EF-Tu and EF-Ts and in eukaryotes eEF1.
Translocation is movement of ribosome on mRNA. It requires EF -G in prokaryotes and eEF2 in eukaryotes.
(iii) Chain termination. The termination of polypeptide is signalled by one of the three terminal codons in the mRNA. The three terminal codons are UAG (Amber), UAA (Ochre) and UGA (Opal).
A GTP dependent factor known as release factor is associated with termination codon. It is eRF1 in eukaryotes and RF1 and RF2 in prokaryotes.
At the time of termination, the terminal codon immediately follows the last amino acid codon. After this, the polypeptide chain, tRNA, mRNA are released and the subunits of ribosomes get dissociated.
Concept Builder
There are some metabolic inhibitors which inhibit the synthesis of proteins in bacteria. These antibiotics are used in checking the growth of certain bacteria which are pathogenic in nature e.g.,
Tetracycline - Inhibits binding of amino-acyl tRNA to ribosomes
Streptomycin - Inhibits initiation of translation and causes misreading
Choloramphenicol - Inhibits peptidyl transferase activity
Erythromycin - Inhibits translocation of mRNA along ribosomes
Neomycin - Inhibits interaction between tRNA and mRNA.
Gene expression is the mechanism at the molecular level by which a gene is able to express itself in the phenotype of an organism.
In the translation unit, mRNA has some sequences that are not translated and are referred to as untranslated regions (UTR).
The UTRs are present at both 5' end (before start codon) and at 3' end (after stop codon).
They are required for efficient translation process.
Regulation of gene expression
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
REGULATION OF GENE EXPRESSION
1. Constitutive genes are those genes which are constantly expressing themselves in a cell because their products are required for the normal cellular activities, e.g., genes for glycolysis, ATPase.
2. Non-constitutive genes are not always expressing themselves in a cell. These are called Luxury genes. They are switched on or off according to the requirement of cellular activities, e.g., gene for nitrate reductase in plants, lactose system in Escherichia coli.
This provides maximum functional efficiency to the cell. Such regulated genes, therefore are required to be switched 'on' and 'off' when a particular function is to begin or stop.
This regulation can be achieved by anyone of the following two processes:
(1) Induction. This is a process of gene regulation where addition of a substrate stimulates or induces synthesis of enzymes needed for its own breakdown.
(2) Repression. In this process of gene regulation, addition of end product stops the synthesis of enzymes needed for its formation. This phenomenon is also known as feedback repression.
Operon
Francois Jacob and Jacques Monod (1961) proposed a model of gene regulation, known as Operon model.
Operon is a co-ordinated group of genes such as structural genes, operator gene, promoter gene, regulator gene which function or transcribe together and regulate a metabolic pathway as a unit.
Inducible operon (lac operon)
In Escherichia coli, breakdown of lactose requires three enzymes.
These enzymes are synthesized together in a co-ordinated manner and the unit is known as lac operon.
Since the addition of lactose itself stimulates the production of required enzymes, it is also known as inducible system.
Lac operon
lac operon consists of following genes :
(1) Structural genes. These genes code for the proteins needed by the cell which include enzymes or other proteins having structural functions.
In lac-operon, there are following three structural genes:
(i) lac a -gene coding for enzyme transacetylase
(ii) lac y -gene coding for enzyme permease
(iii) lac z -gene coding for enzyme -galactosidase
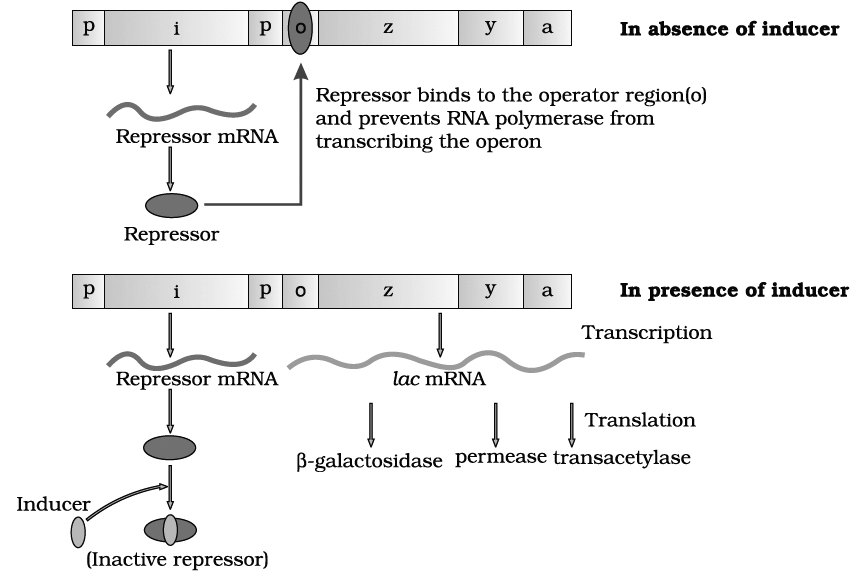
(2) Operator gene (o). It interacts with a protein molecule (the regulator molecule), which promotes (induce) or prevents (repress) the transcription of structural genes.
(3) Promoter gene (p). This gene is the recognition point where RNA polymerase remains associated.
(4) Regulator gene (i). This is generally known as inhibitory gene (i). This gene codes for a protein called the repressor protein. It is an allosteric protein which can exist in two forms. In one form, it is paratactic to an operator and binds with it and in another form it is paratactic to inducer (like lactose).
The operon is switched 'off' and 'on'.
The transcription or function of lac genes or structural genes depends upon operator gene.
When repressor protein produced by inhibitory gene (i) or regulatory gene binds to operator (o) gene, RNA polymerase gets blocked. There would be no transcription and the operon model remains in 'switched off' position.
On the other hand, when inducer like lactose is added, the repressor protein (produced by gene i) gets bound to it.
The repressor, therefore, gets released from the operator.
RNA polymerase is now permitted to act.
Hence, the transcription of lac genes now takes place and the operon model is in 'switched on' position.
All the three genes are transcribed by RNA polymerase to form a single mRNA strand.
Each gene segment of mRNA is called cistron and, therefore, mRNA strand transcribed by more than one gene is known as polycistronic.
Tryptophan Operon -Repressible Operon System
Operon model can also be explained using feed-back repression.
In tryptophan (trp) operon, three enzymes are necessary for the synthesis of amino acid tryptophan.
These enzymes are synthesized by the activity of five different genes in a co-ordinated manner.
The addition of tryptophan, however, stops the production of these enzymes.
Thus, the system is known as repressible system.
In this system, there are five structural genes, trp A, trp B, trp C, trp D and trp E, coding for three enzyme needed for the synthesis of tryptophan, an amino acid.
Regulatory gene (R) produces repressor protein which is known as apo-repressor because it does not get bound to the operator directly.
Hence, the operator gene remains in 'switched on' position.
Tryptophan when added, binds to the apo-repressor and is called co-repressor.
This apo-repressor and co-repressor complex (activated repressor) now binds to operator gene and blocks the function of RNA polymerase.
Thus, transcription would not occur and tryptophan operon would be in 'switched off' position.
Feed-back repression is functional when there is no further need of the end product and, hence, there is no requirement of continuation of this anabolic pathway.
This operon stops the process.
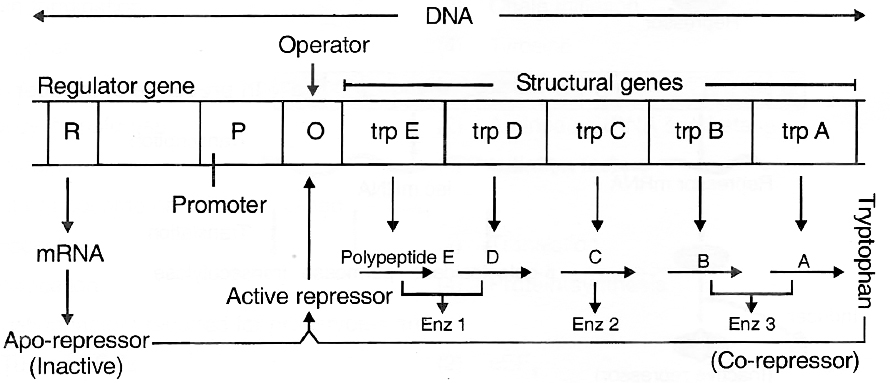
Tryptophan operon model of gene regulation in bacteria
In the prokaryotes, control of the rate of transcriptional initiation is the predominant site for control of gene expression.
Regulation of Gene Expression in Eukaryotes
In eukaryotes, the regulation of gene expression could be exerted at four levels:
(i) Transcriptional level (formation of primary transcript)
(ii) Processing level (regulation of splicing)
(iii) Transport of mRNA from nucleus to the cytoplasm
(iv) Translational level
In eukaryotes, functionally related genes do not represent an operon but are present on different sites in chromosomes.
Here, structural gene is called split gene which is a mosaic of exons and introns, i.e., base triplet -amino acid matching is not continuous.
Britten -Davidson gene battery model is most popular for eukaryotic genes.
It proposes the occurrence of 5-types of genes-producer, receptor, integrator, sensor and enhancer-silencer.
Exons are coding part of cistron that forms RNA.
Introns are non-translated part of DNA called IVS (intervening sequences) or spacer DNA.
An intron begins with GU and ends up with an AG.
However, the entire split gene is transcribed to form a continuous strip of hn-RNA.
This removal of non-coding intronic part and fusion of exonic coding parts of RNA is called RNA splicing. About 50-90% of primary transcribed RNA is discarded during processing.
Human genome project
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
Human Genome Project (HGP)
The Human genome project was the international, collaborative research program whose goal was the complete mapping and understanding of all the genes of human beings.
All genes together are known as "genome".
The Human Genome Project as "Mega project" was a 13 year project co-ordinated by the U.S. Department of Energy and the National Institute of Health.
An International Human Genome project was launched in the year 1990 and completed in 2003.
The International Human Genome sequencing consortium published the first draft of the human genome in the journal Nature in February 2001 .
Human genome is said to have approximately 3 × 109 bp, and the cost of sequencing required is US $ 3 per bp. The total estimated cost of the project would be approximately 9 billion US dollars. In human genome 20,000 to 25,000 genes are present, out of them smallest gene is TDF gene with 14 bp and largest gene is Duchenne Muscular Dystrophy gene with 2400 × 103 bp.
Organisms and the number of bp and genes in them
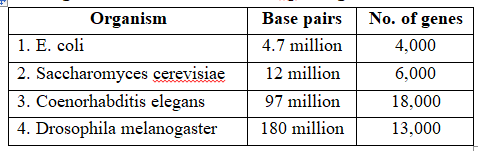
Following are the important goals of HGP :Goals of HGP
(i) Identication of all the approximately 20,000 -25,000 genes in human DNA.
(ii) To determine the sequence of the 3 billion chemical base pairs that make up human DNA.
(iii) To store this information in databases.
(iv) To improve tools for data analysis.
(v) Transfer related technologies to other sectors, such as industries.
(vi) Bioinformatics, i.e., close association of HGP with the rapid development of a new area in biology.
(vii) Sequencing of model organisms -Complete genome sequence of E.coli, Saccharomyces cerevisiae, Coenorhabditis elegans; Drosophila melanogaster, D. pseudoobscura, Oryza sativa and Arabidopsis was achieved in April, 2003.
(viii) Adress the ethical, legal and social issues (ELSI) that may arise from the project.
Concept Builder
Key Definitions :
1. cDNA: It stands for complementary DNA, a synthetic type of DNA generated from mRNA. By using mRNA as template, scientists use enzymatic reactions to convert its information back into cDNA and then clone it as cDNA library. These libraries are important to scientists because they consist of clones of all protein -encoding DNA or all the genes in the human genome.
2. Mb : Mb stands for megabase, a unit of length equal to 1 million base pairs and roughly equal to 1cM. (1cM = 1 million bp)
3. Microarray: Microarrays are devices used in many types of large scale genetic analysis. They can be used to study how large number of genes are expressed as messenger RNA in a particular tissue and how a cell's regulatory network control vast batteries of genes simultaneously.
Methodologies
The HGP techniques include:
(i) Sequence tagged site: It is a short DNA segment that occurs only once in a genome and whose exact location and order of bases is known. STSs serve as landmarks on the physical map of a genome. It is also called as Expressed Sequence Tags (ESTs). The genes that are expressed as RNA are referred to as ESTs.
(ii) Sequencing the whole set of genome that contained all the coding and non-coding sequences, and later assigning different regions in the sequence with functions, known as Sequence Annotation.
(iii) The Employment of Restriction Fragment Length Polymorphism (RFLP)
(iv) Yeast Artificial Chromosomes (YACs)
(v) Bacterial Artificial Chromosomes (BACs)
(vi) Polymerase chain reaction (PCR)
(vii) Electrophoresis
For sequencing, the total DNA from a cell is isolated and converted into random fragments of relatively smaller sizes (recall DNA is a very long polymer, and there are technical limitations in sequencin very long pieces DNA) and cloned in suitable host using specialised vectors.
The cloning resulted into amplification of each piece of DNA fragment so that it subsequently could be sequenced with ease.
The commonly used hosts were bacteria and yeast, and the vectors were called as BAC (bacterial artificial chromosomes), and YAC (yeast artificial chromosomes).
The fragments were sequenced using automated DNA sequencers that worked on the principle of a method developed by Frederick Sanger. These sequences were then arranged based on some overlapping regions present in them. This required generation of overlapping fragments for sequencing. Alignment of these sequences was humanly not possible. Therefore, specialised computer based programs were developed. These sequences were subsequently annotated and were assigned to each chromosome. The sequence of chromosome 1 was completed only in May 2006 (this was the last of the 24 human chromosomes -22 autosomes and X and Y -to be sequenced).
Salient Features of Human Genome
Some of the salient observations drawn from human genome project are as follows :
(i) The human genome contains 3164.7 million nucleotide bases.
(ii) The average gene consists of 3000 bases, but sizes vary greatly, with the largest known human gene being dystrophin at 2.4 million bases.
(iii) The total number of genes is estimated at 30,000-much lower than previous estimates of 80,000 to 1,40,000 genes. Almost all (99.9 percent) nucleotide bases are exactly the same in all people.
(iv) The functions are unknown for over 50 per cent of discovered genes.
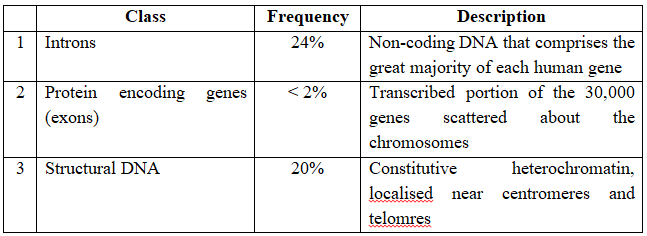
(v) Less than 2 percent of the genome codes for proteins.
(vi) Repeated sequences make up very large portion of the human genome.
(vii) Repetitive sequences are stretches of DNA sequences that are repeated many times, sometimes hundred to thousand times. They are thought to have no direct coding functions, but they shed light on chromosome structure, dynamics and evolution.
(viii) Chromosome 1 has most genes (2968), and the Y has the fewest (231).
(ix) Scientists have identified about 1.4 million locations where single-base DNA differences (SNPs -single nucleotide polymorphism, pronounced as 'snips') occur in humans. This information promises to revolutionise the processes of finding chromosomal locations for disease-associated sequences and tracing numan history.
Classes of DNA sequences found in Human Genome
Francis Collins, director of the public funded genome project predicts the following progress in the next thirty years:Future Thrust of Human Genome Project
By 2010
1. Scientists will have developed accurate predictive tests for atleast a dozen common diseases so that preventive measures may be taken in advance.
2. Infertility specialists will be using the sophisticated techniques of pre-implantation genetic diagnosis to screen embryos for genetic disorders and designer babies.
3. Medicines will be making use of gene therapy.
By 2020
1. Doctors will have "designer drugs" to treat almost every disease.
2. Doctors will test patient's genetic make-up before prescribing drugs.
3. Doctors could change the genetic make-up of a living person by germ-line therapy.
4. Treatment of diseases like cancer, schizophrenia, depression etc. will have transformed.
By 2030
1. Genetic-based health care will have completely developed.
2. Most medical researches will be carried out using computer models rather than living tissues of animals.
3. Average life-span will rise up to 90 years.
The Indian Scenario
The Indian gene centre accounts for 160 species out of 2400 species in all of the 12 megagene centres.
Though the plant genetic resources activities got intensified in India in the first half of the century, but received the required impetus after creation of NBPGR in 1976 which has headquarters at IARI (Indian Agricultural Research Institute), New Delhi and several regional sub centres at different agroclimatic zones like Jodhpur (Arid areas), Trichur (Humid Tropical Zone), Shillong (Eastern sub tropical/subtemperate zone) etc.
As on 31 st March 1996, NBPGR holds 15,4,533 accessions of various agri-horticultural crops.
National Facility for Plant Tissue Culture Repository (NFPTCR) was established in 1986 by department of biotechnology at NBPGR for conservation of germplasm of vegetatively propagated plants.
Concept Builder
1. In translation, ribosomes are often found in clusters linked together by a strand of mRNA. This complex (polyribosome or polysome) enables several molecules of the same polypeptide to be produced simultaneously.
2. In vitro synthesis of gene was made by Hargobind Khorana (1968). He was able to link 77 nucleotide base pairs to code for yeast tRNAalanine. Later on in 1976, he synthesized a functional gene by linking 207 base pairs to code for E.coli. tRNA tyrosine.
3. Jumping genes (Transposon or Transposable element) discovered by Babara McClintock in maize can change their position within or between two chromosomes.
4. In some viruses a part of genetic material function for two or more genes (cistrons). Such genes are called overlapping genes. They were discovered by Borrel in × 174.
5. Transgenosis is the transmission of genetic information to plant cells by bacteriophage or phenomenon of transfer, gene maintenance, transcription and function.
6. Siblings (also sibship or sibs) : Individuals having the same parents; brother-sister relationship.
7. Genetic marker. A gene mutation that has phenotypic effects useful for tracing the chromosome on which it is located.
8. Phenocopy: An individual who has a phenotype similar to that produced by a certain mutant genotype, even though the individual may not have that genotype.
9. Charles Weismann isolated the gene (cDNA) for interferon from human lymphocytes and cloned it in E. coli and yeast.
10. Some Other Important Contributions of Scientists
(i) Zacharis - Called nuclein as DNA and proved that chromatin is rich in DNA
(ii) Fuelgen - DNA is located in nucleus where chromosomes are found, nucleus is fuelgen positive
(iii) Behrem - Nucleic acid is of two types DNA and RNA.
(iv) Fischer - Identified purines and pyrimidines in nucleic acid.
(v) Levene - Studied chemistry of DNA and found that DNA has deoxyribose sugar and four types of nucleotides.
(vi) Sanger - Determined base sequence in nucleic acid.
(vii) Hedges and Jacob -Term "transposon"
DNA fingerprinting
- Books Name
- A TEXT OF BIOLOGY - CLASS XII
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 12
- Subject
- Biology
DNA FINGERPRINTING
What is DNA Fingerprinting?
The chemical structure of everyone's DNA is the same.
The only difference between people (or any animal) is the order of the base pairs.
There are so many millions of base pairs in each person's DNA that every person has a different sequence.
Using these sequences, every person could be identified solely by the sequence of their base pairs.
However, there are so many millions of base pairs due to which the task would be very time consuming.
Instead, scientists are able to use a shorter method, because of repeating base patterns in DNA (Satellite DNA).
These patterns do not, however, give an individual "fingerprint," but they are able to determine whether two DNA samples are from the same person, related people, or non-related individuals.
VNTR's, RFLP, SSR, RAPD
Every strand of DNA has stretches that contain genetic information which are responsible for an organism's development (exons) and stretches that, apparently, supply no relevant genetic information at all (introns).
Although the introns may seem useless, it has been found that they contain repeated sequences of base pairs.
These sequences are called Variable Number Tandem Repeats (VNTRs).
VNTR's also called minisatellites were discovered by Alec Jeffreys et. al. of U.K.
These consist of hypervariable repeat regions of DNA having a basic repeat sequence of 11-60 bp and flanked on both sides by restriction sites.
The number of repeats show a very high degree of polymophism and the size of VNTR varies from 0.1 to 20 Kb. The length of minisatellites and position of restriction sites is different for each person.
Therefore, when the genomes of two people are cut using the same restriction enzyme, the length and number of fragments obtained is different for both.
This is called RFLP or Restriction Fragment Length Polymorphism.
These fragments, when separated by gel electrophoresis, and obtained on a Southern Blot, constitutes what is called DNA fingerprint.
Father of DNA fingerprinting is Alec Jeffreys while the Indian experts Lalji Singh and V.K. Kashyap are known as Father of Indian technique.
Concept Builder
Now-a-days RAPD's or Randomly Amplified Polymorphic DNA are used for DNA fingerprinting (pronounced 'rapid').
It is a simpler technique than RFLP.
The DNA sequences flanking microsatellites (or SSRs i.e., simple sequence repeats or short tandem repeats) on both sides are conserved, so one can select primers complementary for these sequences and put these along with the genome in a thermal cycler.
The PCR will amplify the intervening microsatellites which can also be radiolabelled by using 32p.
The microsatellites have simple sequences of 1-6 bp. repeated hundreds of times.
Methodology of DNA fingerprinting
The Southern Blot is one way to analyze the genetic patterns which appear in a person's DNA. It was devised by E.M.Southern (1975) for separating DNA fragments. Performing a Southern Blot involves:
1. Isolating the desired DNA. It can be done either chemically, by using a detergent to wash the extra material from the DNA, or mechanically, by applying a large amount of pressure in order to "squeeze out" the DNA.
2. Cutting the DNA into several pieces of different size. This is done using one or more restriction enzymes.
3. Sorting the DNA pieces by size. The process by which the size separation is done is called gel electrophoresis. The DNA is poured into a gel, such as agarose, and an electrical charge is applied to the gel, with the positive charge at the bottom and the negative charge at the top. Because DNA has a slightly negative charge, the pieces of DNA will be attracted towards the bottom of the gel. The smaller pieces, however, will be able to move more quickly and thus, further towards the bottom than the larger pieces. The different-sized pieces of DNA will therefore, be separated by size, with the smaller pieces-towards the bottom and the larger pieces towards the top.
4. Denaturing the DNA fragments, so that all of the DNA is rendered single-stranded. This can be done either by heating or chemically treating the DNA in the gel using alkali.
5. Blotting the DNA. The gel with the size-fractionated. DNA is applied to a sheet of nitrocellulose paper or nylon membrane, and then baked to permanently attach the DNA to the sheet. The Southern Blot is now ready to be analyzed.
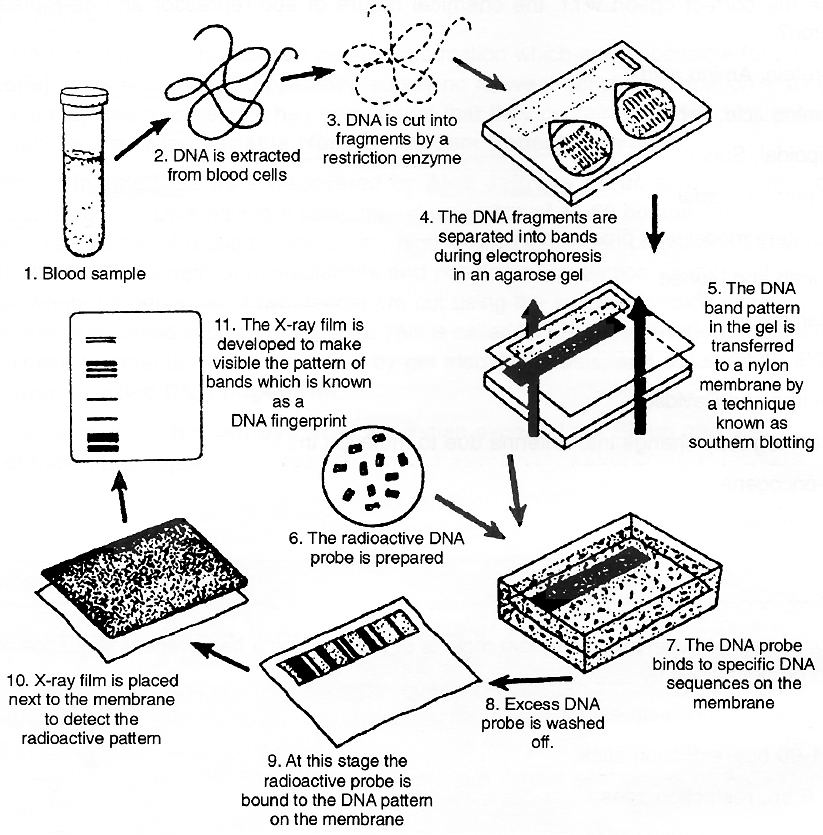
The DNA fingerprinting process
In order to analyze a Southern Blot, a radioactive genetic probe is used in a hybridization reaction with the DNA in question. If an X-ray is taken of the Southern Blot after a radioactive probe has been allowed to bound with the denatured DNA on the paper, only the areas where the radioactive probe binds will Show themselves on the film (autoradiography). This allows researchers to identify, in a particular person's DNA, the occurrence and frequency of the particular genetic pattern contained in the probe.
Practical Applications of DNA Fingerprinting
1. Solving Cases of Disputed Paternity and Maternity: Because a person inherits his or her VNTRs from his or her parents, VNTR patterns can be used to establish paternity and maternity.
2. Criminal Identification and Forensics: DNA isolated from blood, hair, skin cells, or other genetic evidence left at the scene of a crime can be compared, through VNTR patterns, with the DNA of a criminal suspect to determine guilt or innocence.
3. Personal Identification : The notion of using DNA fingerprints as a sort of genetic bar code to identify individuals has been discussed, but this is not likely to happen anytime in the near future. The technology required to isolate, keep on file, and then analyze millions of very specified VNTR patterns is both expensive and impractical.
GENOMICS
Application of DNA sequencing and genome mapping to the study, design and manufacture of biologically important molecules is known as genomics.
It is comparatively more recent branch in the field of biology.
The term genomics was introduced by Thomas Roderick.
In genomics, function of gene is identified by using the technique of reverse genetics.
Genomics study may be classified into three classes:
(i) Structural genomics : It involves mapping and sequencing of genes.
(ii) Functional genomics : It involves the identification of function of a particular gene.
(iii) Application genomics : It involves use of genomics information for crop improvement etc.
Complete genomics of Arabidopsis and rice have been worked out and they are having 130 and 430 million base pairs respectively.
