 ACME SMART PUBLICATION
ACME SMART PUBLICATION
How to Analyse Chemical Composition?
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
Protoplasm is a complex mixture of both organic and inorganic compounds.
Molecules found in the protoplasm of cells are called biomolecules.
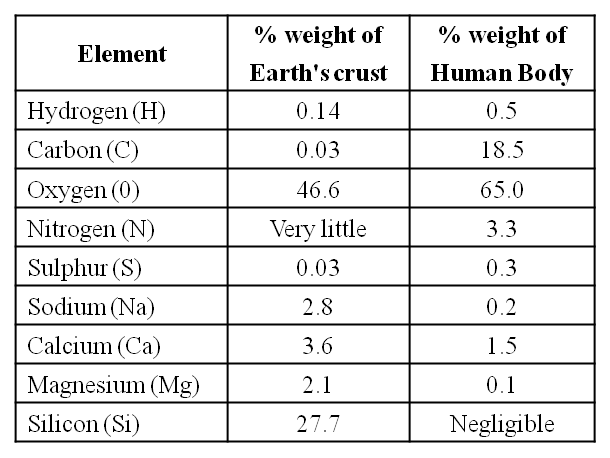
A Comparison of Elements Present in Non-living and Living matter
The collection of various types of molecules in a cell is called the cellular pool.
The cellular pool consists of various types of biomolecules such as : (a) water (b) inorganic materials (c) organic compounds.
The small molecules of low molecular weight, simple molecular conformations and higher solubilities are called micromolecules.
These include minerals, water, amino acids, simple sugars and nucleotides.
The various minerals found in cells have many uses.
Mitochondria are rich in manganese.
Molybdenum is necessary for fixation of nitrogen catalysed by the enzyme nitrogenase.
Copper occurs in cytochrome oxidase.
Magnesium is essential for a large number of enzymes, particularly those utilising ATP.
Ca and Mg decrease the excitability of nerves and muscles.
(i) Sodium and potassium are responsible for the maintenance of extracellular and intracellular fluids through the osmotic effects of their concentration. These two ions are also responsible for the maintenance of membrane potential and transmission of electrical impulses in the nerve cells. Both in cells and in extracellular fluids, diabasic phosphate (HPO42–) and monobasic phosphate (H2PO42–) act as acidbase buffers to maintain the H+ ion concentration.
(ii) The most abundant element in cell/living matter is oxygen. O > C > N > H
(iii) Fe++ and Cu++ are found in cytochromes.
(iv) The concentration of the cations inside the cell is K > Na > Ca.
How To Analyse Chemical Composition?
In order to study the various biomolecules found in living tissues (a vegetable or a piece of liver etc.), the tissue is ground in trichloroacetic acid (Cl3CCOOH) using pestle and mortar.
The resultant slurry is strained through cheese cloth or cotton and we obtain two fractions.
The filtrate is called acid soluble pool while the retentate is called acid insoluble fraction.
The acid soluble pool represents roughly the cytoplasmic composition.
The macro molecules from cytoplasm and organelles become the acid-insoluble fraction.
Chemicals present in both the fractions are further separated by various analytical techniques and identified.
Average Composition of Cells
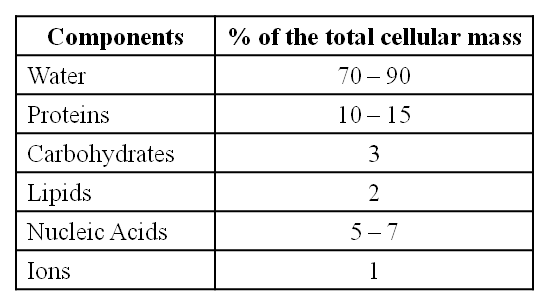
Note : Protein > Nucleic acid > Carbohydrates > Lipids
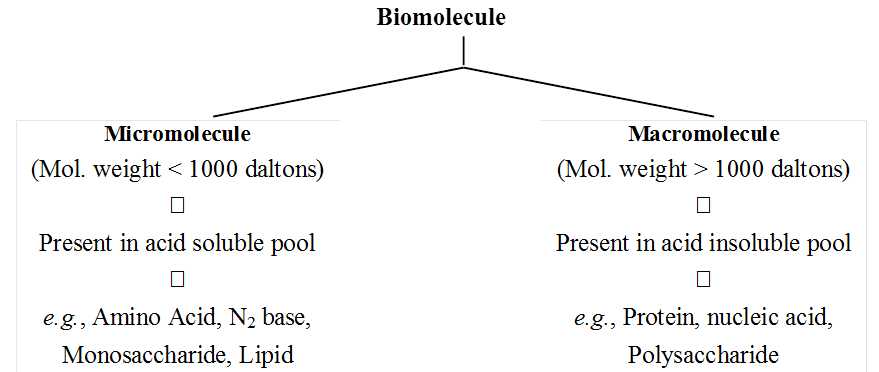
The acid soluble pool contains chemicals called biomicromolecules as they have small molecular mass of 18-800 daltons approximately.
The acid insoluble fraction contains chemicals with large molecular mass of more than 800 daltons, they are biomacromolecules.
Biomacromolcules are large size, high molecular weight, complex molecules that are formed by condensation of biomicromolecules.
Their molecular mass is in the range of ten thousand daltons and above.
Biomacromolecules are of three types-proteins, nucleic acids and polysaccharides.
Note : Though lipids have a molecular mass similar to that of micromolecules i.e. less than 800 Da, but they do not appear in the acid Soluble pool due to their non-polar nature.
All biomacromolecules are polymers except lipids.
Polymers are formed by process of union of repeating subunits, each subunit being called monomer.
Monomers are simple small sized low molecular weight molecules which cannot be hydrolysed further into smaller subunits.
Polymers occur in the form of threads.
They are folded variously to form three-dimensional shapes required for their functioning.
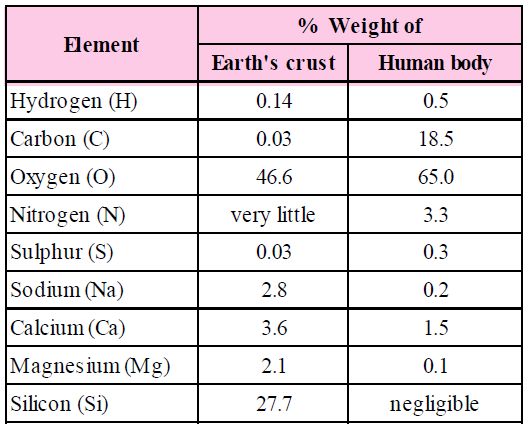
A list of Representative Inorganic Constituents of Living Tissues

Depending upon the molecular weight and solubility, biomolecules are divided into two categories.
(a) Micromolecules are small sized, have low molecular weight, simple molecular structure and high solubility in the intracellular fluid matrix. These include water, mineralrs, gases, carbohydrates, lipids, amino acids and nucleotides.
(b) Macromolecules are large sized, have larger molecular weight, complex conformation and low solubility in the intracellular fluid matrix. They are generally formed by polymerisation of micromolecules. These include polysaccharides, proteins and nucleic acids.
Analytical techniques, when applied to the compound give us an idea of the molecular formula and the probable structure of the compound.
All the carbon compounds that we get from living tissue can be called "Biomolecules".
However, living organisms also have inorganic elements and compounds.
When the tissue is fully burnt all carbon compounds are oxidised to gaseous form (CO2, water vapour) and are removed.
What is remaining is called "Ash".
This ash contains inorganic elements (like calcium, magnesium etc.).
Inorganic compounds like sulphate, phosphate etc. are also seen in the acid soluble fraction.
Therefore, elemental analysis gives elemental composition of living tissues in the form of H, O, Cl, C etc. while analysis of compounds gives an idea of the kind of organic and inorganic constituents present in living tissues.
From a chemistry point of view, one can identify functional groups like aldehydes, ketones, aromatic compounds etc.
But from a biological point of view, we shall classify them into aminoacids, nucleotide bases, fatty acids etc.
How to Analyse Chemical Composition?
Chapter 9
Biomolecules
The biosphere has a vast variety of living species. Carbon, hydrogen, oxygen, and numerous other elements, as well as their respective contents, are acquired per unit mass of living tissue when an elemental analysis is done on plant tissue, animal tissue, or microbial paste. A similar list of elements will be obtained if the same analysis is performed on a piece of the earth's crust as an example of non-living stuff. A sample of live tissue contains all of the elements found in a sample of the earth's crust. However, a closer look reveals that any living organism has a higher relative quantity of carbon and hydrogen in relation to other elements than the earth's crust.
How to Analyse Chemical Composition?
A natural substance's elemental analysis reveals that it is made up of several elements such as carbon, hydrogen, oxygen, chlorine, and so on. Analytical procedures provide information on various organic and inorganic compounds, as well as their molecular formulas and structures. They also aid in the separation and purification of one component from another. Simple experiments can be used to determine the chemical composition of biomolecules. Crush and combine a piece of living tissue with an acid. We get two pieces after filtering it. The acid-soluble fraction of the filtrate is retained on the filter membrane, while the acid-insoluble fraction is retained on the filter membrane. This indicates that there are two or more substances with distinct characteristics within the tissues.Thousands of organic molecules have been discovered in the acid-soluble pool by scientists.

Constituents of Living Tissues
Take another piece and burn it till all the moisture in it is evaporated. When carbon compounds are burned, they are all oxidized. Inorganic substances such as calcium, magnesium, sulfate, phosphate, and others are formed in the tissue by the ash that has been left out.
Analytical techniques, when applied to a chemical, provide us with an estimate of its molecular formula and likely structure. 'Biomolecules' refers to all carbon compounds obtained from living tissues. All carbon-containing chemicals (organic compounds) found in living organisms are classified as biomolecules. They are organic substances found in living cells that have a role in the organism's maintenance and metabolic activities. Inorganic elements and compounds, on the other hand, are found in living beings. As a result, elemental analysis provides information on the composition of live tissues in terms of hydrogen, oxygen, chlorine, carbon, and other elements, whereas compound analysis provides information on the types of organic and inorganic constituents found in living tissues.
Functional groups such as aldehydes, ketones, aromatic molecules, and others can be detected in living tissues from a chemical standpoint. However, amino acids, nucleotide bases, fatty acids, and carbohydrates make up living tissues from a biological standpoint.
Amino acids are chemical molecules that have both an amino and an acidic group as substituents on the same carbon, the -carbon. As a result, they are known as -amino acids. They're methanes that have been replaced. The four valency locations are occupied by four substituent groups. Hydrogen, carboxyl group, amino group, and a variable group known as R group are the four groups. There are numerous amino acids in the R group due to its nature. However, there are only twenty varieties of those found in proteins. The R group in these proteinaceous amino acids could be a hydrogen (glycine), a methyl group (alanine), hydroxy methyl (serine), or something else entirely. The amino, carboxyl, and R functional groups make up the chemical and physical properties of amino acids.Acidic (e.g., glutamic acid), basic (lysine), and neutral (valine) amino acids are classified by the number of amino and carboxyl groups they contain.
Similarly, aromatic amino acids exist (tyrosine, phenylalanine, tryptophan). The ionizability of the –NH2 and –COOH groups of amino acids is a unique feature. As a result, the structure of amino acids alters in different pH solutions.
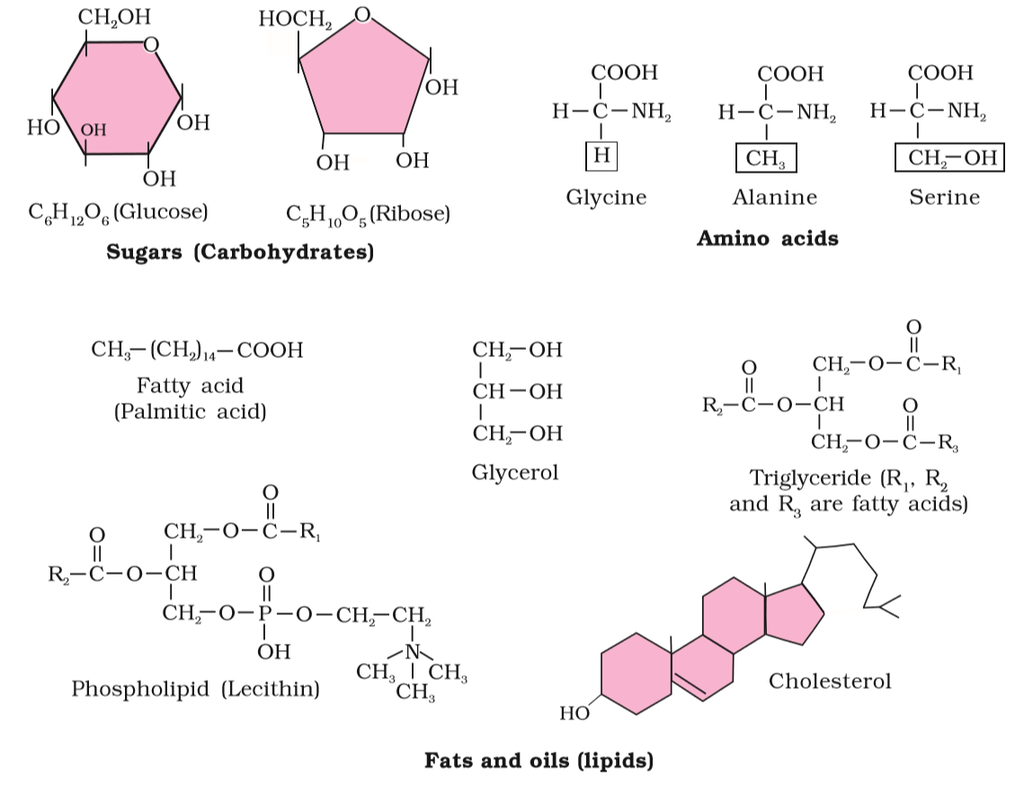
Figure 2 (a): Diagrammatic representation of small molecular weight organic compounds in living tissues
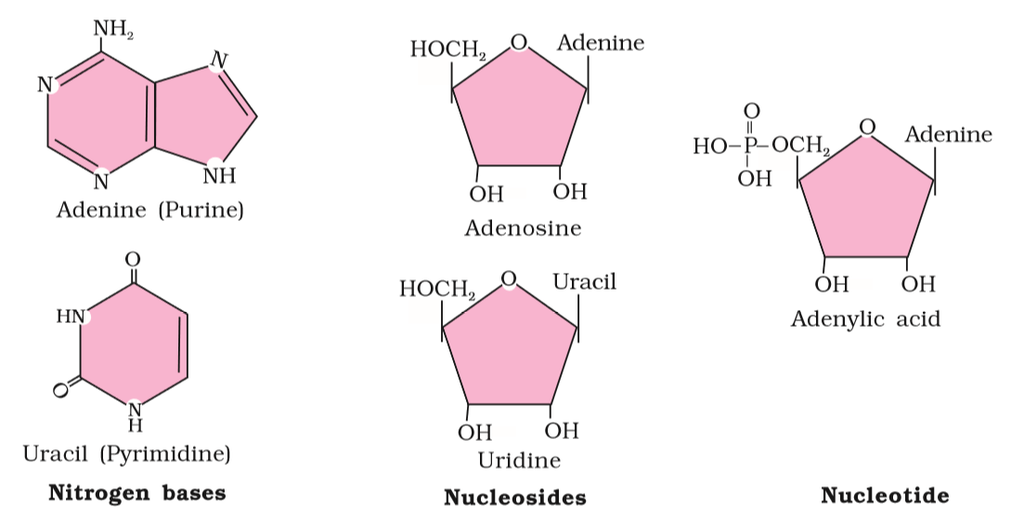
Figure 2(b): Diagrammatic representation of small molecular weight organic compounds in living tissues
Heterocyclic rings can be found in a variety of carbon compounds found in living beings. Adenine, guanine, cytosine, uracil, and thymine are examples of nitrogen bases. They're called nucleosides when they're found linked to sugar. Nucleotides are formed when a phosphate group is additionally esterified to the sugar. Nucleosides include adenosine, guanosine, thymidine, uridine, and cytidine. Nucleotides include adenylic acid, thymidylic acid, guanylic acid, uridylic acid, and cytidylic acid. Only nucleotides make up nucleic acids like DNA and RNA. DNA and RNA are two types of genetic material.
Primary and Secondary Metabolites
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
PRIMARY AND SECONDARY METABOLITES
The most exciting aspect of chemistry deals with isolating thousands of compounds, small and big, from living organisms, determining their structure and if possible synthesising them.
If one were to make a list of biomolecules, such a list would have thousands of organic compounds including amino acids, sugars, etc.
We can call these biomolecules as 'metabolites'.
In animal tissues, one notices the presence of all such categories of compounds. For example, proteins, carbohydrates, fats, amino acids, nucleic acids.
These are called primary metabolites.
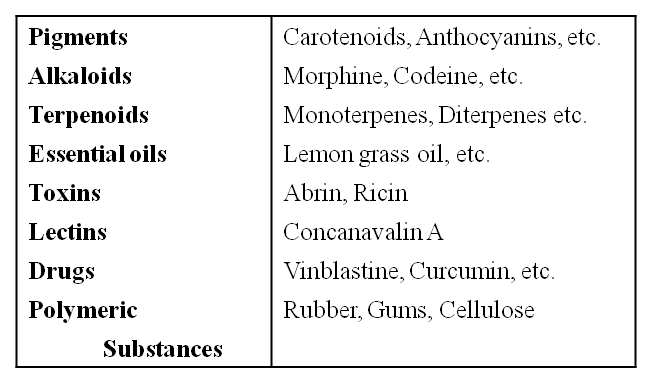
However, when one analyses plant, fungal and microbial cells, one would see thousands of compounds other than these primary metabolites which are called secondary metabolites, such as alkaloids, flavonoids, rubber, essential oils, antibiotics, coloured pigments, scents, gums and spices.
Difference between in Primary and Secondary Metabolites
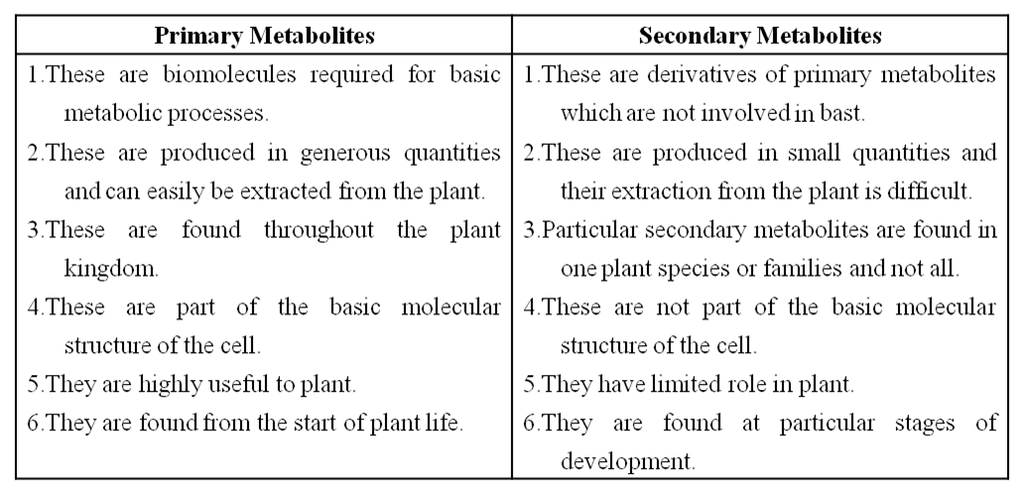
Primary metabolites have identifiable functions and play known roles in normal physiological processes.
While many of the secondary metabolites are useful to 'human welfare' (e.g., rubber, drugs, spices, scents and pigments) their physiological role is unknown.
Some secondary metabolites have ecological importance too.
Some Secondary Metabolites
Let us take a detailed look at various micromolecules and macromolecules in a cell.
Primary and Secondary Metabolites
Primary and Secondary Metabolites
The most interesting component of chemistry is extracting thousands of small and large chemicals from live creatures, establishing their structure, and, if possible, synthesizing them. A list of biomolecules might contain thousands of organic chemicals, such as amino acids, carbohydrates, and other substances. These biomolecules can be referred to as metabolites. All of these kinds of chemicals can be found in animal tissues. Primary metabolites are what these are called. Thousands of additional substances termed secondary metabolites can be found in the plant, fungal, and microbial cells, such as alkaloids, flavonoids, rubber, essential oils, antibiotics, colored pigments, fragrances, gums, and spices. Secondary metabolites are what these are called.While primary metabolites have well-defined functions and roles in normal physiological processes, the role and functions of all secondary metabolites' in host organisms are currently unknown. Many of them, however, are beneficial to 'human welfare (e.g., rubber, drugs, spices, scents and pigments). Secondary metabolites play an important role in ecology.
Biomacromolecules
Proteins, nucleic acids, polysaccharides, and lipids are the only organic molecules found in the acid-insoluble fraction. With the exception of lipids, these substances have molecular weights in the tens of thousands of Daltons or higher. Biomolecules, or chemical substances found in living beings, are divided into two categories for this reason. One, those which have molecular weights less than one thousand daltons and are commonly referred to as micromolecules or simply biomolecules whereas those which are discovered in the acid-insoluble fraction are dubbed macromolecules or biomacromolecules. All of the chemicals in the acid-soluble pool have one thing in common. They have molecular weights that range from 18 to 800 daltons (Da).
With the exception of lipids, the molecules in the insoluble fraction are polymeric. Lipids are small molecular weight substances that can be found in a variety of forms, including cell membranes and other membranes. When the cell structure is disturbed and the tissue ispulverized, the breakdown of cell membranes and other membranes results in the formation of vesicles that are not water-soluble. As a result, membrane fragments in the form of vesicles separate from the acid-insoluble pool, resulting in the macromolecular fraction. The cytoplasmic composition is generally represented by the acid-soluble pool. The acid-insoluble fraction contains macromolecules from the cytoplasm and organelles. They represent the total chemical composition of biological tissues when put together.In summation, it is observed that water is the most abundant component in living organisms upon characterizing the chemical makeup of living tissue from the standpoint of abundance and classifying them accordingly.
Carbohydrates
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
Carbohydrates
Carbohydrates are mainly compounds of carbon, hydrogen and oxygen.
Carbohydrates are so called because in most of them, the proportion of hydrogen and oxygen is the same as in water (H2O) i.e., 2 : 1.
These are also known as saccharides (compounds containing sugar).
Carbohydrates are produced by green plants during photosynthesis.
These constitute about 80% of the dry weight of plants.
Carbohydrates are divided into 3 main classes -monosaccharides, oligosaccharides and polysaccharides.
1. Monosaccharides
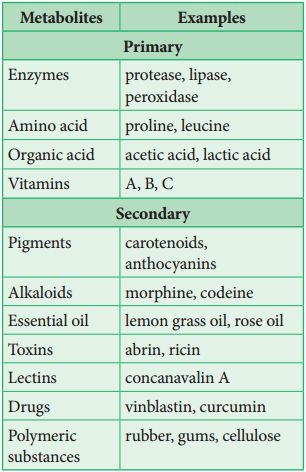
(i) These are single saccharide units with CnH2nOn general formula which cannot be hydrolysed further into still smaller carbohydrates. These are composed of 3-7 carbon atoms and are classified according to the number of C atoms as trioses (3C), tetroses (4C), pentoses (5C), hexoses (6C) and heptoses (7C). Of these, pentoses and hexoses are most common. Monosaccharides are important as energy sources and as building blocks for the synthesis of large molecules.
(ii) All monosaccharides are either aldoses or ketoses. Simplest monosaccharides include trioses e.g., glyceraldehyde and dihydroxyacetone.
(iii) Tetroses (e.g., erythrose) are rare. Erythrose takes part in the synthesis of lignin and anthocyanin pigments.
(iv) Ribose, ribulose, xylulose and arabinoses are pentoses. Xyluloses and arabinoses polymerise to form xylans and arabans which are cell wall material.
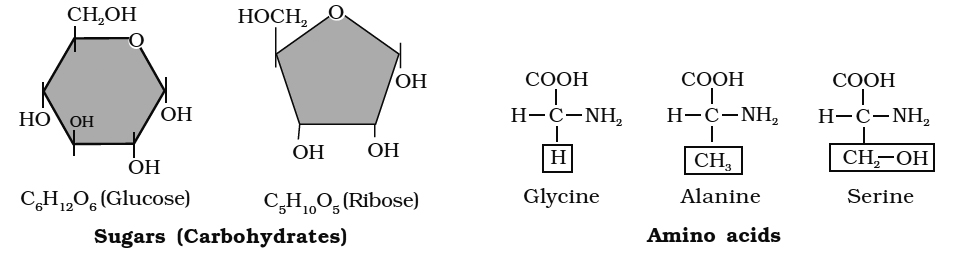
(v) Glucose, fructose, mannose, galactose are hexoses. These are white, sweet-tasting, crystalline and extremely soluble in water.
(vi) Glucose is called universal sugar and is also known as dextrose or grape sugar or corn sugar.
(vii) Fructose is called fruit sugar and is also known as levulose. It is the naturally occurring sweetest sugar. Honey has two sugars -Dextrose and Levulose.
(viii) Heptoses have 7 carbon atoms per molecule of sugar with general formula C7H14O7 e.g., sedoheptulose. It is an intermediate of respiratory and photosynthetic pathways.
Pentoses and hexoses of monosaccharides occur in solid forms i.e., open chain and ring chain. There are two types of ring chains i.e.,
(a) pyranose ring, which has hexagonal shape with 5 carbon atoms and one oxygen atom and
(b) furanose ring, which has pentagonal shape with 4 carbon atoms and one oxygen atom.
(ix) Monosaccharides have 'free' aldehyde or ketone group which can reduce Cu++ to Cu+. Hence, these are also called reducing sugars.
(x) Monosaccharides have two important chemical properties.
(a) Sugars having a free aldehyde or ketone group can reduce Cu++ to Cu+. These are called reducing sugars. This property is the basis of Benedict's test and Fehling's test to detect the presence of glucose in urine.
(b) The aldehyde or ketone group of monosaccharide can react and bind with an alcoholic group of another organic compound to join the two compounds together. This bond is called the glycosidic bond. This bond can be hydrolysed to give the original reactants.
Differences between Reducing and Non-reducing Sugar

Concept Builder
Derived Monosaccharides
(i) Deoxysugar -Loss of oxygen atom at 2nd carbon of ribose, yields deoxyribose, a constituent of DNA.
(ii) Amino sugar -Monosaccharides having an amino group e.g. glucosamine, galactosamine
(iii) Sugar acid -e.g., Ascorbic acid, glucuronic acid, galacturonic acid.
(iv) Sugar alcohol -e.g., glycerol and mannitol (present in brown algae).
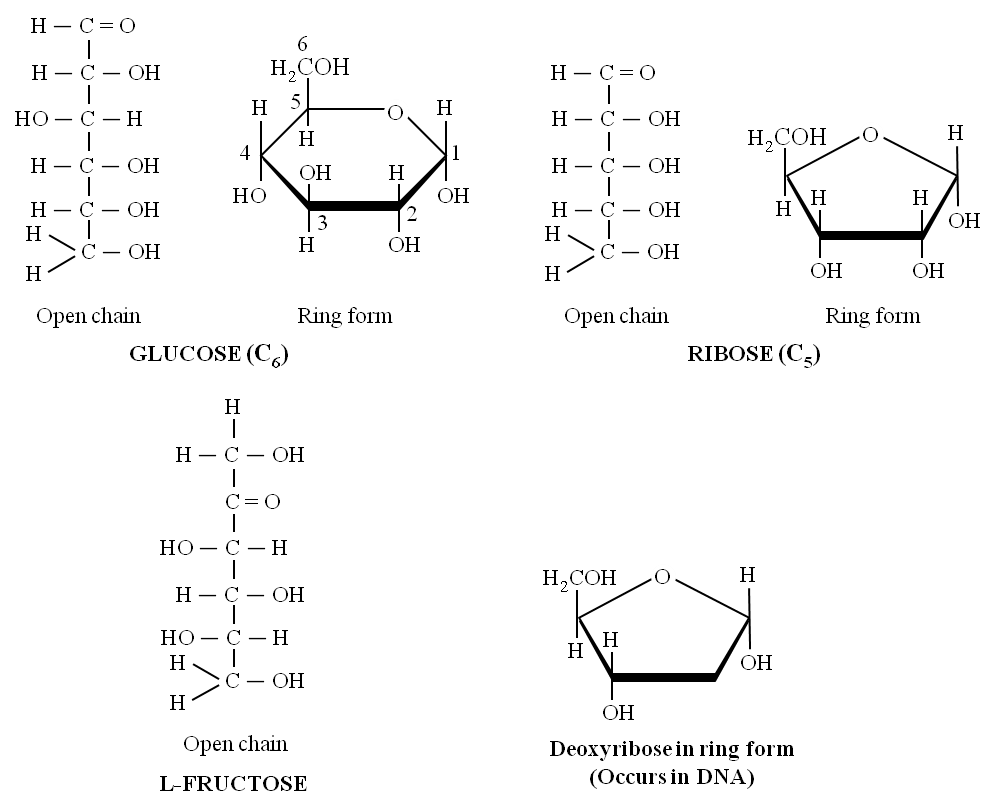
3. Oligosaccharides : They are condensation product of (2-9) monosaccharides. These include diasaccharides, trisaccharides, tetrasaccharides, hexasaccharides, heptasaccharides etc.
Differences between Oligosaccharides and Polysaccharides
(a) Disaccharides:
These are formed by condensation reactions between two monosaccharides (usually hexoses).
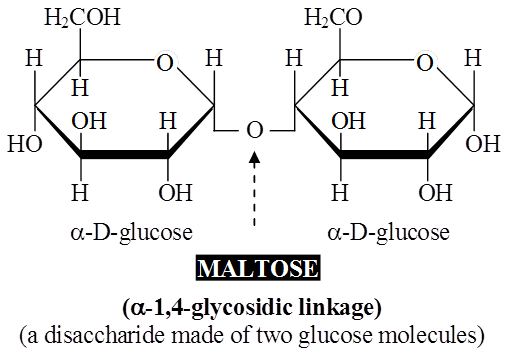
The bond formed between two monosaccharides is called a glycosidic bond.
It normally forms between C-atoms 1 and 4 of neighbouring units (1, 4 bond).
Once linked, the monosaccharide units are called residues.
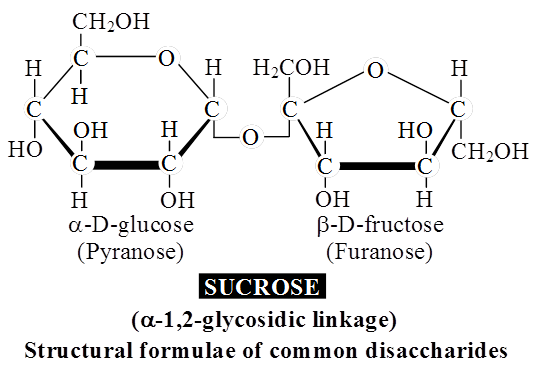
A molecule of sucrose is formed from a molecule of glucose and one of fructose.
Sucrose is the storage product of photosynthesis in sugarcane and sugarbeet.
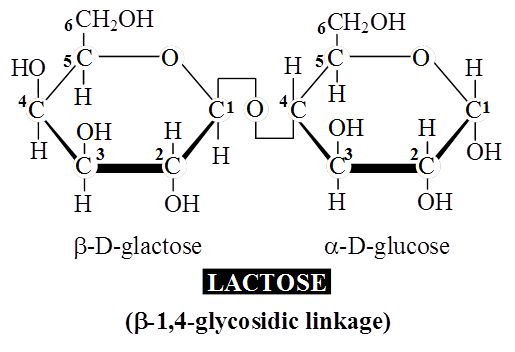
Lactose or milk sugar is found in human milk and cow's milk.
It is formed from one glucose molecule and one of galactose.
Maltose or malt sugar is formed from two molecules of glucose during germination of starchy seeds.
Maltose and lactose are reducing disaccharides.
Sucrose does not reduce Cu++ to Cu+, hence sucrose is a non-reducing sugar.
(b) Trisaccharides:
Sugars composed of 3 monosaccharide units are called trisaccharides (e.g. raffinose).
Raffinose is a common trisaccharide found in plants.
Upon hydrolysis, it yields one molecule each of glucose, fructose and galactose.
Larger oligosaccharides are attached to the cell membrane and enable the cell-cell recognition due to their presence.
They also take part in antigen specificity.
4. Polysaccharides
These are polymers of monosaccharides and are branched or unbranched linear molecular chains.
These are insoluble carbohydrates and are considered to be non-sugars.
Starch, glycogen, cellulose, pectin, hemicellulose, inulin are polysaccharides.
Body cells store carbohydrates as polysaccharides since these are easy to store and can be easily converted back into simple carbohydrates upon hydrolysis. These are in more condensed form and they have high molecular weight. These cannot pass through the plasma membrane.
Polysaccharides are of two types :
(i) Homopolysaccharides - consist of only one type of monosaccharide monomer e.g. starch, glycogen and cellulose, fructan, xylan, araban, galactan.
(ii) Heteropolysaccharides - consist of more than one type of monosaccharide monomer e.g. chitin, agar, arabanogalactans, arabanoxylans etc.
Polysaccharides are of three main types -storage (e.g. starch and glycogen), structural (e.g. chitin, cellulose) and mucopolysaccharides (e.g. keratan sulphate, chondroitin sulphate, hyaluronic acid, agar, alginic acid, carrageenin and heparin).
(a) Storage Polysaccharides
Food-Storage Polysaccharides: Starch is found abundantly in rice, wheat and other cereal grains legumes, potato, tapioca and bananas.
It is formed during photosynthesis and serves as an energystoring material.
Glycogen found in liver and muscles stores energy in mammals.
Storing carbohydrates in the form of polysaccharides has two advantages.
During their formation, many molecules of water are removed from monosaccharides.
This helps in condensing the bulk to be stored.
Unlike small carbohydrates, polysaccharides are relatively easy to store.
When necessary, polysaccharides are broken down by enzymes for the release of energy.
Starch
Starch, glycogen and inulin are reserve food materials.
Starch is a polymer of a-D-glucose. It is the major reserve food in plants.
Starch has two components -amylose (an unbranched polymer) and amylopectin (a branched polymer).
Amylopectin: Consists of 2000 -200,000 glucose molecules forming straight chain and shows branching (after 25 glucose units). Branching point has , 1-6 glycosidic linkage.
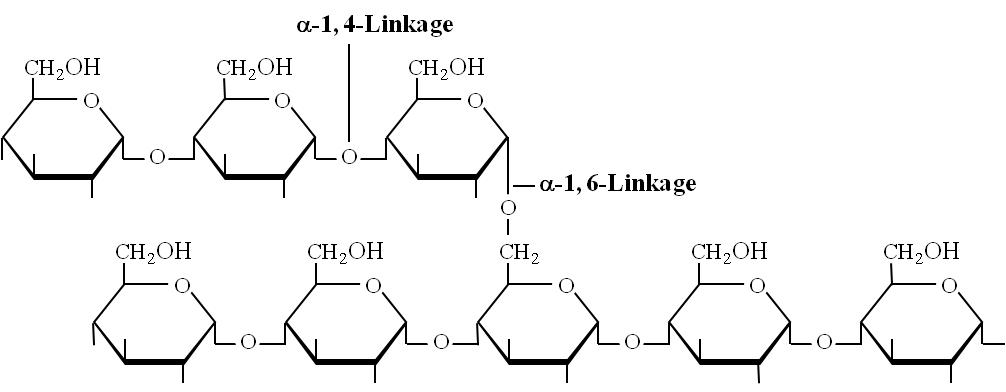
Amylopectin (branched polysaccharide)
Amylose: Consists of , 1-4 glycosidic linkage between -D glucose molecules. It is a straight chain of 200 -1000 glucose units. Starch forms helical secondary structures, each turn consists of 6 glucose units.
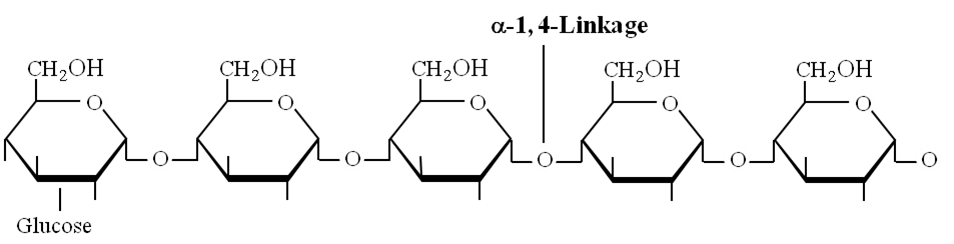
Structure of amylose showing -1, 4 linkage
Concept Builder
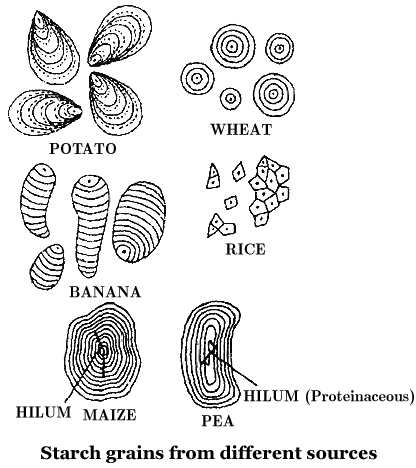
Starch molecules accumulate in the form of layers (stratifications) around a shifting organic centre (hilum) to form starch grains.
Hilum is made up of protein. In eccentric starch grains, hilum lies on one side.
These are found in potatoes.
In concentric starch grains, hilum is present in the centre.
These are found in wheat, maize, pea.
Dumb-bell shaped starch grains are found in the latex of Euphorbia.
Starch grains with single hilum are called simple (e.g. maize) but those with more than one hilum are called compound (e.g. potato, rice).
Starch turns blue with iodine as the helices in starch hold I2.
(ii) Glycogen: Glycogen is the animal equivalent of starch, many fungi also store it. Glycogen turns red-violet with iodine.
It consists of 30,000 glucose units joined by , 1-4 bonds, much more branched than starch. Branch point has , 1-6 linkages and branching occurs after 10-14 glucose units.
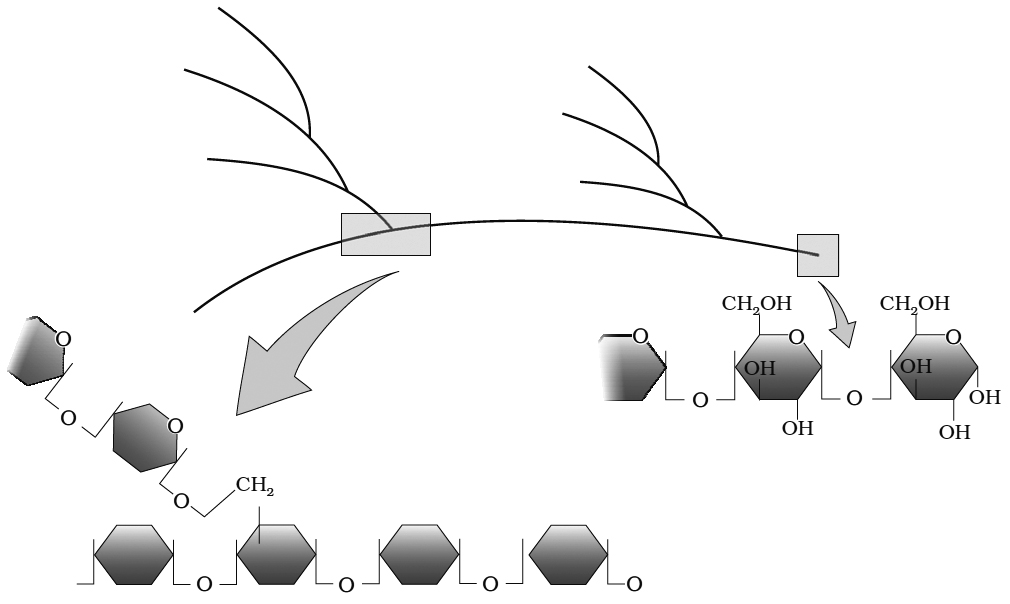
Diagrammatic representation of a portion of glycogen
(iii) Inulin: It is an unusual polysaccharide and polymer of fructose. It is stored particularly in roots and tubers of the family Compositae e.g. Dahlia tubers.
(b) Structural Polysaccharides Cellulose (Hexosan polysaccharide) :
Cellulose is the main structural unbranched homopolysaccharic of plants.
One molecule of cellulose has about 6000 -glucose residues.
Cotton fibres contain the largest amount (90 percent) of cellulose among natural materials.
Wood contains between 25 to 50 percent cellulose, the rest being hemicellulose and lignin.
Fibres of cotton, linen and jute are used for textile and ropes.
The artificial fibre Rayon is manufactured by dissolving cellulosic materials in alkali and by extruding and coagulating the filaments.
By treatment with other chemicals, cellulose is converted into Cellulose Acetate (used in fabrics, cellulosic plastics and shatter-proof glass), Cellulose Nitrate (used in propeliant explosives) and Carboxymethyl Cellulose (added to ice creams, cosmetics and medicines to emulsify and give a smooth texture).
Cellulose can be hydrolysed to soluble sugars.
Microbes can then convert these sugars to form ethanol, butanol, acetone, methane and other useful chemicals.
Cellulose is unbranched homopolysaccharide of -glucose.
Cellulose is the most abundant carbohydrate in biosphere.
Cellulose is produced by plants and is used for building cell walls. Cellulose is the most abundant organic compound in the biosphere.
Wood and cotton contain large quantities of cellulose.
Chitin is a polysaccharide found in the exoskeleton of insects, crabs and prawns.
Chitin is similar to cellulose in many ways except that its basic unit is not glucose, but a similar molecule that contains nitrogen (N-acetylglucosamine).
Although chitin is soft and leathery, it becomes hard when impregnated with calcium carbonate or certain proteins.
The insolubility of these polysaccharides in water helps to retain the form and strengthens the structure of organisms.
Pectin and hemicellulose: Pectin and hemicelluloses are structural polysaccharides.
Pectins are made up of arabinose, galactose and galacturonic acid.
Pectic acid is an acidic polysaccharide of methyl ester of D-galacturonic acid.
Middle lamella which binds the cells together is composed of calcium pectate.
Due to this substance, water absorption capacity of cell wall is increased.
Fruit walls contain high percentage of pectin.
During ripening, pectin breaks down into simple sugars resulting in the sweetening and loosening of fruits.
Hemicellulose is a mixture of D-xylose linked by 1-4 glycosidic bond.
Xylans, arabans, galactans are hemicelluloses. Food such as dates -Phoenix have hemicellulose as reserve food.
(c) Mucopolysaccharides
The slimy substances produced by plants are called mucilages.
When you soak the seeds of isabgol (Plantago ovata) or cut the fruit of okra (bhindi), you will notice the presence of a slimy substance.
Mucilages are polysaccharides formed from galactose and mannose.
Many seaweeds yield mucilages of commercial value such as agar, alginic acid and carrageenin.
Mucopolysaccharides are found in cell walls of bacteria and in the connective tissues of animals, as well as in body fluids.
These bind proteins in cell walls and connective tissue and water in interstitial spaces thereby providing lubrication in ligaments and tendons.
The vitreous humor of the eye and synovial fluid also contain mucopolysaccharides.
Hyaluronic acid is found in connective tissue and in cell walls.
Keratin sulphate and chondroitin sulphate occur in cartilage, cornea and the skin and impart strength and flexibility to them.
Keratan sulphate - consists of acetyl glucosamine, galactose and sulphuric acid, provides strength and flexibility to skin and cornea.
Hyaluronic acid -consists of D-glucuronic acid and N-acetyl glucosamine, present in the vitreous humor of eye, synovial fluid and cerebrospinal fluid etc.
Heparin is a polymer of sulfated glucosamine and sulfated iduronic acid.
It is an anticoagulant present in human blood.
Husk of Plantago ovata and mucilage of Aloe barbadensis are medicinally used.
Agar, alginic acid carrageenin are obtained from marine algae.
Artificial silk is polysaccharide prepared from rayon.
Carbohydrates
Carbohydrates
Carbohydrate is a group of organic compounds occurring in living tissues and foods in the form of starch, cellulose, and sugars. It is one of the three micronutrients via which a human body obtains energy. The properties of carbohydrate biology include carbon, hydrogen, and oxygen atoms at their chemical level. Cn(H2O)n is the generic formula for all carbohydrates. This formula is only valid for simple sugars, which are made up of the same amount of carbon and water.
There are two types of carbohydrates, simple and complex. This division is primarily based on their chemical structure along with their degree of polymerization.
Simple Carbohydrates: Simple carbohydrates carry one or two molecules of sugar. Such examples of carbohydrates are found abundantly in dairy products, refined sugar, etc. Since these carbohydrates do not comprise any fiber, vitamin, or mineral, they are regarded as empty calories. Simple carbohydrates can be further divided into three categories. These are as follows:
Monosaccharides: Carbohydrates consisting of one sugar molecule are called monosaccharides. Monosaccharides can be further classified based on the number of carbon atoms. These are trioses, tetroses, pentoses, hexoses, and heptoses. One of the most significant monosaccharides is glucose. The following are the two most frequent methods for preparing glucose. Sucrose is converted to glucose and fructose when it is cooked with dilute acid in an alcohol solution. From Starch, Glucose can also be made by hydrolyzing starch and boiling it with weak sulphuric acid at 393 degrees Fahrenheit under high pressure. Glucose, commonly known as dextrose and aldohexose, is abundant on the planet.
Disaccharides: Two monosaccharides combine to form a disaccharide. Sucrose, Lactose, and Maltose are some of the prime examples of this carbohydrate.
Oligosaccharides: Carbohydrates consisting of 2-9 monomers are classified as oligosaccharides.
The term “monosaccharide” refers to a carbohydrate derivative possessing a single carbon chain; “disaccharide” and “trisaccharide” refer to molecules containing two or three such monosaccharide units joined together by acetal or ketal linkages. “Oligosaccharide” and “polysaccharide” refer to larger such aggregates, with “a few” and many monosaccharide units, respectively. Current usage seems to draw the distinction between “few” and many at around 10 units.
Complex Carbohydrate: Complex carbohydrates are made up of two or more molecules of sugar. Such carbohydrates are found abundantly in food items like corn, lentils, peanuts, beans, etc. Complex carbohydrates are also known as polysaccharides as they are formed due to polymerization.
Polysaccharides are another macromolecule family found in the acid-insoluble pellet. Polysaccharides are lengthy sugar chains. They're threads (literally, cotton threads) made up of various monosaccharides as building blocks. cellulose, for example, is a polymeric polysaccharide made up of only one type of monosaccharide, glucose. Cellulose is a homopolymer, which means it is made up of only one type of molecule. Starch is a type of this that is found in plant tissues as a source of energy. Glycogen is a different type of carbohydrate found in animals. Inulin is a fructose polymer. The right end of a polysaccharide chain (such as glycogen) is known as the reducing end, while the left end is known as the non-reducing end. It has branches. Secondary helical structures are formed by starch.In fact, the helical part of starch can retain I2 molecules. The colour of starch-I2 is blue. Because cellulose lacks complex helices, it is unable to retain I2.
Cellulose is the main component of plant cell walls. Cellulosic paper is created from plant pulp and cotton fibre. In nature, there exist more complicated polysaccharides. Amino-sugars and chemically modified sugars are used as building blocks (e.g., glucosamine, N-acetyl galactosamine, etc.). Arthropod exoskeletons, for example, contain a complex polymer called chitin. The majority of these complex polysaccharides are homopolymers.
Amino Acids
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
AMINO ACIDS
Amino acids are small molecules made of carbon, hydrogen, oxygen and nitrogen and in some cases also sulphur.
Each amino acid has a free amino group, a free carboxyl group and 'R' as side chain as same substituents on same carbon atom.
Amino group leads basic character while carboxylic group leads acidic character to the molecule.
Lysine and arginine are Basic Amino Acids because they carry two amino groups and one carboxylic group.
Glutamic acid (glutamate) and aspartic acid (aspartate) contain one amino and two carboxyl groups each and are classified as Acidic Amino Acids.
Alanine, glycine, valine are Neutral Amino Acids as these contain one amino and one carboxyl group each.
These are 20 different amino acids coded by our DNA that differ in the side chain.
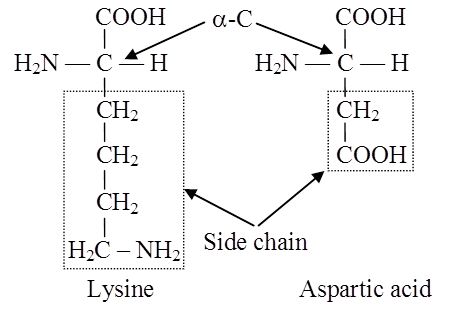
Side chain of a basic and an acidic amino acid
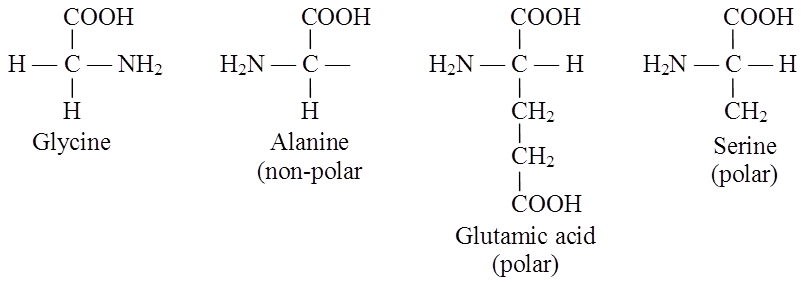
Examples of polar and nonpolar amino acids
Most amino acids are laevo-rotatory while glycine is optically inactive.
There are three important non-protein amino acids.
They are ornithine, citrulline (both are involved in ornithine cycle to synthesise urea) and diaminopimelic acid.
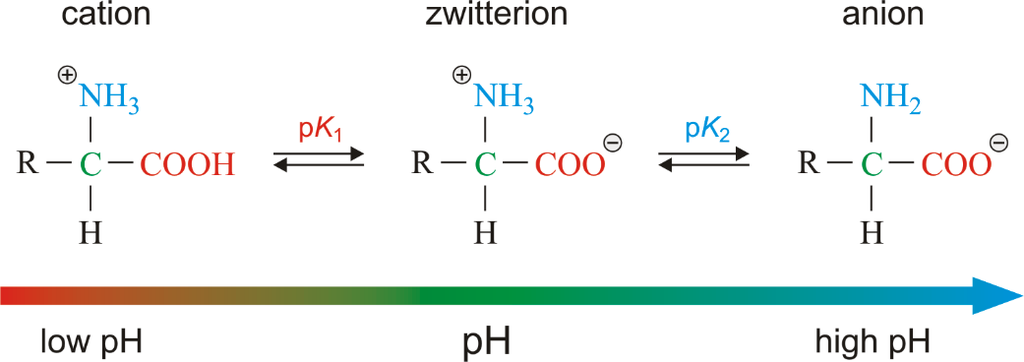
A particular property of amino acids is the ionizable nature of -NH2 and -COOH groups.
Hence, in solutions of different pH, the structure of amino acids changes.
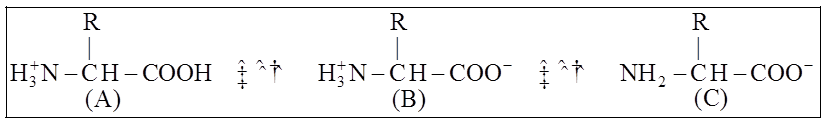
B is called Zwitter ionic form
There are two types of amino acids viz. essential and non-essential amino acids.
Essential amino acids cannot be synthesized by animals whereas non-essential amino acids can be synthesised in animal's body.
There are seven essential amino acids in animals whereas 8 essential amino acids in man.
These are leucine, isoleucine, valine, tryptophan, phenylalanine, lysine and methionine.
Threonine is an additional essential amino acid in human beings.
Two amino acids viz. arginine and histidine are semi-indispensable amino acids as they can be synthesised by human beings but very slowly.
Differences between Essential and Nonessential Amino Acids

Concept Builder
Amino acids are classified into following groups :
(i) Neutral amino acid: With one -NH2 and one -COOH group e.g. glycine, alanine (non-polar).
(ii) Acidic amino acid: Have an extra COOH group (monoamino dicarboxylic), e.g. glutamic and aspartic acid.
(iii) Basic amino acid: Have additional NH2 group (diamino monocarboxylic) e.g. arginine, lysine.
(iv) Sulphur containing amino acid: Have sulphur e.g. cysteine, cystine and methionine.
(v) Alcoholic amino acid: Have -OH group e.g. serine, threonine.
(vi) Aromatic amino acid : Have cyclic structure having a side chain with -COOH and NH2 groups e.g. phenyl alanine, tryptophan, tyrosine.
(vii) Heterocyclic amino acid: N is present in the ring e.g. proline, histidine, hydroxyproline.
(viii) Semi essential amino acid : Arginine and histidine are semi-essential amino acids required by children.
Protein amino acids are laevorotatory and -type except glycine. (Glycine: Simplest amino acid, involved in the formation of heme).
Functions of Amino Acids
Besides their principal function as building blocks for proteins, specific amino acids are also converted into different types of biologically active compounds.
For example, tyrosine is converted into the hormones thyroxine and adrenaline, as well as the skin pigment melanin, glycine is involved in the formation of heme and tryptophan in the formation of the vitamin nicotinamide as well as the plant hormone indole-3-acetic acid.
After the removal of the amino group the carbon chain of many amino acids is converted into glucose.
On losing the carboxyl groups as carbon dioxide, amino acids form biologically active amines such as histamine. Histamine is required for the functioning of muscles, blood capillaries and gastric juices.
Ornithine and citrulline are components of urea cycle.
Antibiotics contain non protein amino acids.
Amino acids form organic acids which form glucose by gluconeogenesis.
Lysine is an essential amino acid because it is not formed in the body and has to be provided through diet.
Amino Acids
Amino Acids
Amino acids are chemical molecules with amino and carboxylate functional groups as well as a side chain that is unique to each amino acid. Amino Acids are chemical substances that combine to produce proteins, which is why they are known as the building blocks of proteins. These biomolecules have a role in a variety of biological and chemical functions in the human body and are essential for human growth and development. There are around 300 amino acids found in nature. Amino acids' general features include:
1. A high melting and boiling point.
2. Amino acids are crystalline solids that are white in color.
3. Few amino acids have a pleasant, tasteless, or bitter flavour.
4. The majority of amino acids are water-soluble and insoluble in organic solvents.
There are 20 amino acids found in nature, all of which have the same structural features: an amino group (-NH3+), a carboxylate group (-COO-), and a hydrogen-bonded to the same carbon atom. Their side-chain, known as the R group, distinguishes them from one another. The - carbon of each amino acid is connected to four distinct groups namely: Amino group, COOH, Hydrogen atom, and Sidechain.
Amino acids have a general structure which can be represented as:
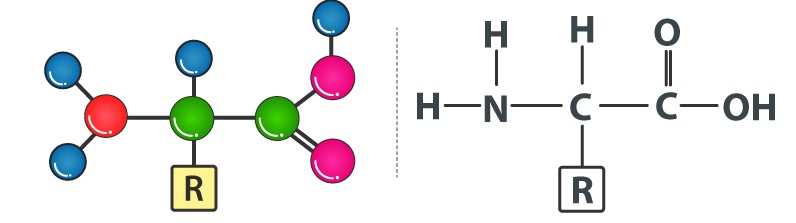
Our bodies can easily produce a few non-essential amino acids out of a total of 20 amino acids. Alanine, asparagine, arginine, aspartic acid, glutamic acid, cysteine, glutamine, proline, glycine, serine, and tyrosine are examples of these amino acids.
Besides these, there are nine other amino acids that are extremely important because our bodies cannot make them. Isoleucine, histidine, lysine, leucine, phenylalanine, tryptophan, methionine, threonine, and valine are examples of important amino acids.
Amino acids are essential for a variety of biological and chemical tasks in our bodies, including tissue construction and repair, enzyme production and activity, food digestion, molecule transportation, and so on. Only a few amino acids can be synthesized by our bodies, thus the rest, known as essential amino acids, must be obtained from protein-rich foods in our daily diet. Plant-based foods with high levels of amino acids include broccoli, beans, beets, pumpkin, cabbage, almonds, dry fruits, chia seeds, oats, peas, carrots, cucumber, green leafy vegetables, onions, soybeans, whole grain, peanuts, legumes, lentils, and so on. Apples, bananas, berries, figs, grapes, melons, oranges, papaya, pineapple, and pomegranates are high in amino acids.Dairy products, eggs, seafood, poultry, beef, pork, and other animal products are examples of other animal goods.
Functions of Essential Amino acids
1. Phenylalanine helps in maintaining a healthy nervous system and in boosting memory power.
2. Valine acts as an important component in promoting muscle growth.
3. Threonine helps in promoting the functions of the immune system.
4. Tryptophan is involved in the production of vitamin B3 and serotonin hormones. This serotonin hormone plays a vital role in maintaining our appetite, regulating sleep and boosting our moods.
5. Isoleucine plays a vital role in the formation of hemoglobin, stimulating the pancreas to synthesize insulin, and transporting oxygen from the lungs to the various parts.
6. Methionine is used in the treatment of kidney stones, maintaining healthy skin and also used in controlling invade of pathogenic bacteria.
7. Leucine is involved in promoting protein synthesis and growth hormones.
8. Lysine is necessary for promoting the formation of antibodies, hormones, and enzymes and in the development and fixation of calcium in bones.
9. Histidine is involved in many enzymatic processes and in the synthesizing of both red blood cells (erythrocytes) and white blood cells (leukocytes).
Functions of Non-Essential Amino acids
1. Alanine functions by removing toxins from our body and in the production of glucose and other amino acids.
2. Cysteine acts as an antioxidant and provides resistance to our body; it is important for making collagen. It affects the texture and elasticity of the skin
3. Glutamine promotes a healthy brain function and is necessary for the synthesis of nucleic acids – DNA and RNA.
4. Glycine is helpful in maintaining the proper cell growth, and its function, and it also plays a vital role in healing wounds. It acts as a neurotransmitter.
5. Glutamic acid acts as a neurotransmitter and is mainly involved in the development and functioning of the human brain.
6. Arginine helps in promoting the synthesis of proteins and hormones, detoxification in the kidneys, healing wounds, and maintaining a healthy immune system.
7. Tyrosine plays a vital role in the production of the thyroid hormones -T3 and T4, in synthesizing a class of neurotransmitters and melanin, which are natural pigments found in our eyes, hair, and skin.
8. Serine helps in promoting muscle growth and in the synthesis of immune system proteins.
9. Asparagine is mainly involved in the transportation of nitrogen into our body cells, formations of purines and pyrimidine for the synthesis of DNA, the development of the nervous system and improving our body stamina.
10. Aspartic acid plays a major role in metabolism and in promoting the synthesis of other amino acids.
11. Proline is mainly involved in the repairing of the tissues and the formation of collagen, preventing the thickening and hardening of the walls of the arteries (arteriosclerosis) and in the regeneration of new skin.
Proteins
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
PROTEINS
Berzelius coined the term protein. Proteins are hetero polymers of amino acids.
Two amino acids can join through amino group of one and carboxylic group of the other forming an anhydro bond (CO-NH linkage) also known as peptide bond by loss of water molecule.
A protein is a heteropolymer and not a homopolymer.
Collagen is the most abundant protein in animal world and Rubisco (Ribulose biphosphate carboxylase oxygenase) is the most abundant protein in the whole biosphere.
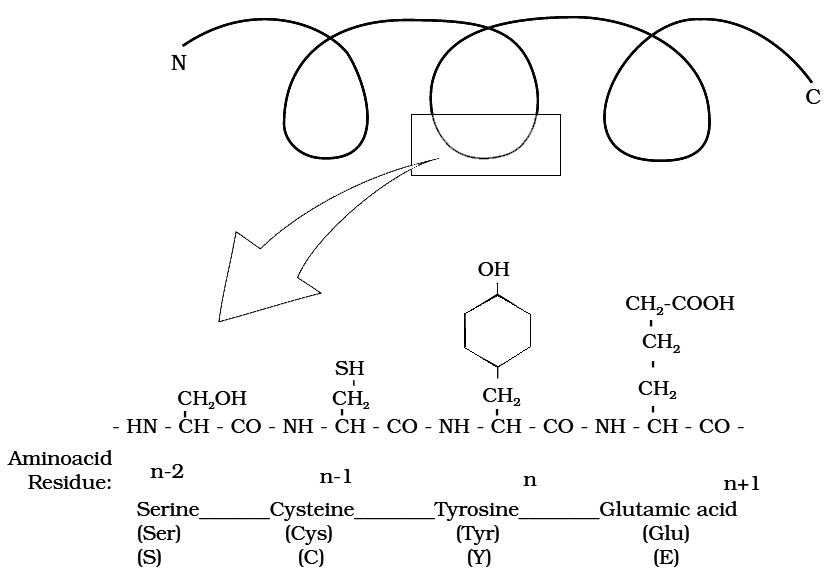
Primary structure of a portion of a hypothetical protein.
N and C refer to the two termini of every protein. Single letter codes and
three letter abbreviations of amino acids are also indicated.
Structure of Proteins :
The four levels of protein structure are:
1. Primary Structrure :
The sequence of amino acids in polypeptide chain gives the protein its Primary Structure.
The primary structure is very important as it determines the specificity of protein but does not make a protein functional.
To be functional the protein must have a particular 3-dimensional structure (conformation).
A functional protein contains one or more polypeptide chains.
The sequence of amino acids in the chain determines where the chain will bend or fold and where the various lengths will be attracted to each other.
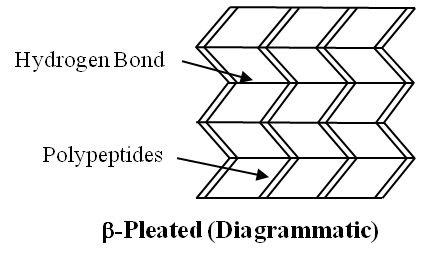
2. Secondary Structure :
Through the formation of hydrogen bonds, peptide chains assumes a Secondary Structure.
When a chain is arranged like a coil it is called an Helix.
When two or more chains are joined together by intermolecular hydrogen bonds, the structure is called Pleated Sheet.
Helical structure is found in keratin of hair and pleated structure found in silk fibres.
Each protein has a specific secondary structure also.
(a) It generailly takes the form of an extended spiral spring, the -helix, whose structure is maintained by many hydrogen bonds which are formed between adjacent -CO and -NH groups. The H atom of the NH group of one amino acid is bonded to the O atom of the CO group three amino acids away. A protein which is entirely helical is keratin.
(b) The other type of secondary structure is called -pleated sheet. Here, two or more chains are joined together by intermolecular hydrogen bonds as in silk fibres.
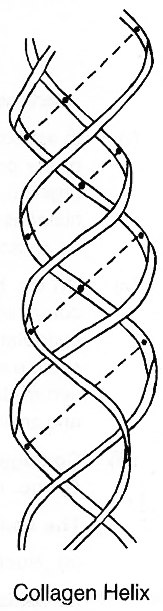
(c) A special secondary structure is observed in collagen or tropocollagen helix which has three strands or polypeptides coiled around one another. The coil is strengthened by the establishment of hydrogen bond between -NH group of glycine residue of each strand with -CO group of the other two strands. Locking effect is due to the proline and hydroxyproline.
3. Tertiary structure :
Usually, the polypeptide chain bends and folds extensively and forms a compact 'globular' shape to obtain functional conformation. This is termed as the tertiary structure.
 Various types of bonds or interactions found during coiling of polypeptide
Various types of bonds or interactions found during coiling of polypeptide
In a large protein like haemoglobin, or in case of an enzyme, the molecule undergoes further folding and coiling to attain functional conformation.
The coils and folds of the protein molecule are so arranged as to hide non-polar amino acid side chains inside and expose the polar side chains.
The 3-dimensional conformation of a protein brings distant amino acid side chains closer.
The active sites of proteins such as enzymes are thus formed.
The conformation of proteins is easily changed by pH, temperature and chemical substances and hence the function of proteins is liable and subject to regulation.
4. Quarternary strucrure :
Many highly complex proteins consist of an aggregation of polypeptide chains held together by hydrophobic interactions and hydrogen and ionic bonds.
Their precise arrangement constitutes the quaternary structure.
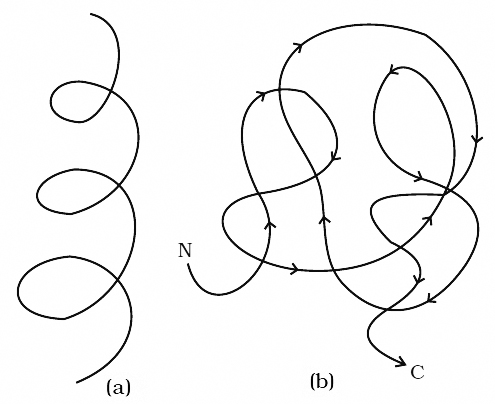
Cartoon showing: (a) A secondary structure and (b) A tertiary structure of proteins
In aqueous media, proteins carry both cationic and anionic groups on the same molecule.
The ionic state of the protein depends on the pH of the medium.
A protein, rich in basic amino acids like lysine and arginine, exists as a cation and behaves as a base at the physiological pH of 7.4 (Basic Protein) e.g., histones of nucleoproteins.
Similady, a protein with acidic amino acids exists as an anion and behaves as an acid e.g., most blood proteins (Acidic Proteins).
Types of Proteins :
On the basis of constitution, proteins are classified as simple or conjugated.
1. Simple Protein :
Simple Proteins are composed of amino acids only.
Some are small, globular molecules mostly soluble in water and not coagulated by heat (e.g., histones).
As the size of the protein molecule increases, it becomes less soluble and its heat-coagulability increases.
For example, larger globular proteins (like egg albumin, serum globulins and glutelins of wheat or rice) are coagulated by heat.
Fibrous proteins have long molecures and are insoluble in water (e.g., keratin of skin and hair and collagen of connective tissues).
2. Conjugated proteins :
Conjugated Proteins are formed by binding of a simple protein with a non-protein called tile Prosthetic Group. e.g., Nucleoproteins have nucleic acids as prosthetic group.
The conjugated proteins are of following types :
(a) Nucleoproteins (prosthetic group-nucleic acid) e.g. protamines
(b) Metalloproteins (prosthetic group-metals) e.g. haemoglobin
(c) Chromoproteins (prosthetic group-pigment) e.g. cytochromes
(d) Phosphoproteins (prosthetic group-phosphoric acid) e.g. Casein of milk.
(e) Lipoproteins (prosthetic group-lipids) e.g. chylomicrons, HDL, LDL etc.
(f) Glycoproteins (prosthetic group-carbohydrates) e.g. mucins
Glycoproteins (and glycolipids) play an important role in cell recognition.
The specificity of this recognition depends upon the particular sequence of sugars in carbohydrate portions.
Ribulose biphosphate carboxylase (an enzyme) present in large amounts in chloroplast stroma is the world's most common protein.
Storage Proteins include albumin of egg and those that occur in seeds (glutelin of wheat). Prolamines are storage proteins.
Protamines are basic proteins associated with DNA of chromosomes, they are rich in lysine and arginine.
P-proteins are involved in the transport of organic compounds through phloem.
Keratin and fibroin form protective structures.
Antibodies are defence proteins.
Snake venom, ricin of castor and bacterial toxins are proteinaceous in nature.
Actin and myosin are essential for muscle contraction.
Microtubules have tubulin protein.
Haemoglobin and myoglobin are transport proteins.
Ovalbumin and glutelin are storage proteins present in cereals. Ferretin is iron storing protein of animal tissues. The type of prolamines and glutelins found in wheat are gliadin and glutenin.
Insulin and parathormone are proteinaceous hormones.
Fibrinogen and thrombin are blood clotting prbteins.
Rhodopsin and iodopsin are photoreceptor pigments. These are present in rods and cones of retina and are proteins.
Proteins having all essential amino acids are called first class proteins.
Monellin, a protein, is the sweetest chemical obtained from an African berry.
Cheese is a denatured protein.
Resilin -is a perfectly elastic protein found in wings of some insects.
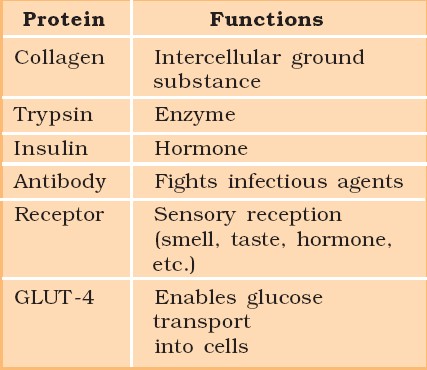
Some proteins and their Functions

Proteins
Proteins
Polypeptides are the building blocks of proteins. They are peptide bonds that connect linear chains of amino acids. A polymer of amino acids makes up each protein. A protein is a heteropolymer, not a homopolymer because there are 20 different types of amino acids. A homopolymer is made up of only one type of monomer that repeats 'n' times. Specific amino acids are necessary for human health and must be obtained through our food. As a result, necessary amino acids are obtained from food proteins. As a result, amino acids can be classified as either essential or non-essential. The latter are those that our bodies can produce, whereas essential amino acids must be obtained through our diet.Proteins have a variety of activities in living creatures, including transporting nutrients across cell membranes, fighting pathogenic organisms, acting as hormones, and enzymatic reactions. The most abundant protein in the animal kingdom is collagen, and the most abundant protein in the biosphere is Ribulose bisphosphate Carboxylase-Oxygenase (RuBisCO).
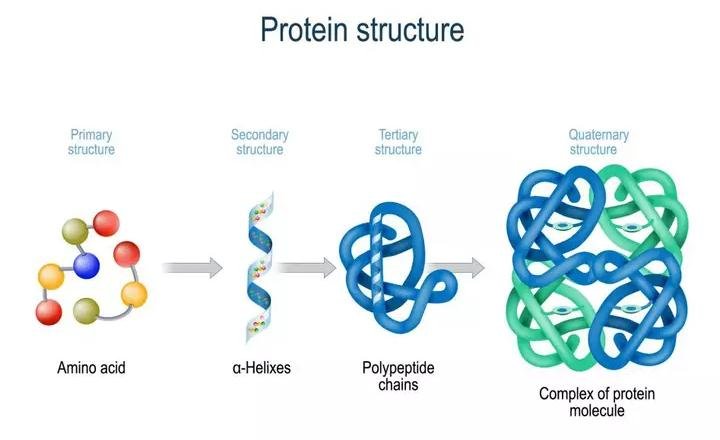
Structure of Proteins:
Proteins are heteropolymers made up of strings of amino acids, as previously stated. In different situations, the structure of molecules means different things. Physicists visualize molecular structures in three dimensions, while biologists explain protein structure on four levels. The primary structure of a protein is the sequence of amino acids, or the positional information in a protein — which amino acid is the first, which is the second, and so on.A protein can be visualized as a line, with the initial amino acid on the left end and the last amino acid on the right.
N-terminal amino acid is another name for the first amino acid. The C-terminal amino acid is the last one in the chain. As an extended stiff rod, a protein thread does not exist throughout. The thread is folded into a helix shape (similar to a revolving staircase). Naturally, only a piece of the protein thread is organized in a helix shape. Only right-handed helices are found in proteins. In what is known as the secondary structure, various portions of the protein thread are folded into other configurations.
Furthermore, the lengthy protein chain folds in on itself like a hollow woollen ball, forming the tertiary structure. This allows us to see a protein in three dimensions. Proteins' tertiary structure is required for many of their biological functions. Some proteins are made up of several polypeptides and subunits. The architecture of a protein, also known as the quaternary structure of a protein, is the way these individual folded polypeptides or subunits are arranged with regard to one other (e.g., a linear string of spheres, spheres placed one upon another in the form of a cube or plate, etc.).Adult human haemoglobin consists of 4 subunits. Two of these are identical to each other. Hence, two subunits of α type and two subunits of β type together constitute the human haemoglobin (Hb).
Nature of bond linking monomers in a polymer
A peptide bond is produced when the carboxyl (-COOH) group of one amino acid combines with the amino (-NH2) group of the next amino acid with the elimination of a water molecule in a polypeptide or protein (the process is called dehydration). Individual monosaccharides in a polysaccharide are joined by a glycosidic bond. Dehydration also contributes to the formation of this link. Two carbon atoms from two neighboring monosaccharides make a peptide bond. A phosphate moiety of a nucleic acid connects the 3'-carbon of one sugar of one nucleotide to the 5'-carbon of the sugar of the next nucleotide. An ester link exists between the phosphate and the sugar's hydroxyl group.The phosphodiester bond is named after the fact that there is one such ester bond on each side.
Lipids
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
LIPIDS
They are made of carbon, hydrogen and little oxygen.
The number of oxygen atoms in a lipid molecule is always less as compared to the number of carbon atoms.
Sometimes small amounts of phosphorus, nitrogen and sulphur are also present.
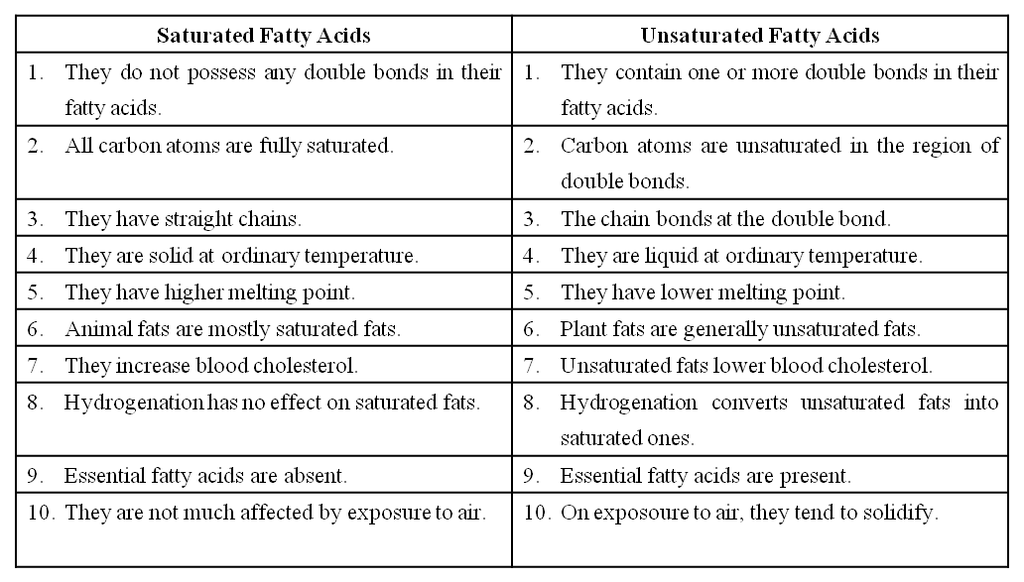
Lipids are insoluble in water, but soluble in non-polar solvents like chloroform and benzene. lipids contain fatty acids which may be saturated or unsaturated.
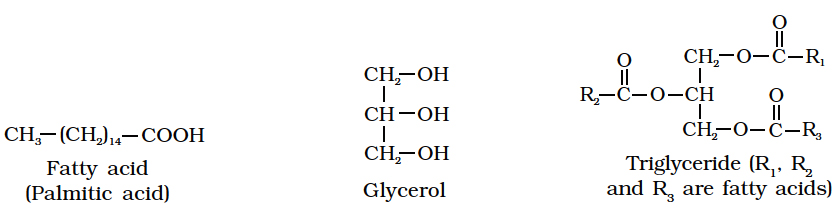
Fatty acids are organic acids with a hydrocarbon chain ending in a carboxyl group (COOH).
Fatty acids are called saturated if they do not have any double bonds between the carbons of the molecular chain e.g., palmitic acid (16 C) and stearic acid (18 C).
Their melting point is high.
CH3(CH2)14COOH CH3(CH2)16COOH General formula of saturated fatty acids
Palmitic acid Stearic acid CnH2nO2
Unsaturated Fatty acids have one or more double bonds between the carbons of the chain.
The 18 C unsaturated fatty acids oleic, linoleic and linolenic acids have 1, 2 and 3 double bonds respectively.
CH3(CH2)7CH = CH(CH2)7COOH General formula of unsaturated fatty acids
Oleic acid CnH2n-2xO2
(where x = number of double bonds)
Arachidonic fatty acid has 4 double bonds.
They have a bend at each double bond which keeps them in liquid form at ordinary temperature.
They are called polyunsaturated fatty acids (PUFA) when they have more than one double bond in them.
They are also called drying oils because they have a tendency to solidify on exposure.
Oils of groundnut, mustard seed, sesame seed and sunflower are rich in unsaturated fatty acids.
The unsaturated fatty acids have lower melting points than saturated fatty acids.
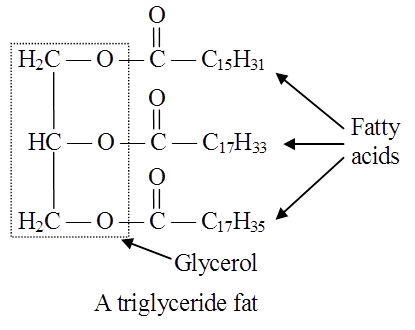
In lipids, fatty acids are usually in the form of esters.
Just as acids and bases react to form salts, similarly organic acids react with alcohol to form esters. Here alcohol is glycerol.
Plants can synthesize all fatty acids.
Animals can not synthesize linoleic, linolenic and arachidonic acid.
These are called essential fatty acids. Their deficiency causes sterility, kidney failure and stunted growth.
Differences between Saturated fatty acids & Unsaturated fatty acids
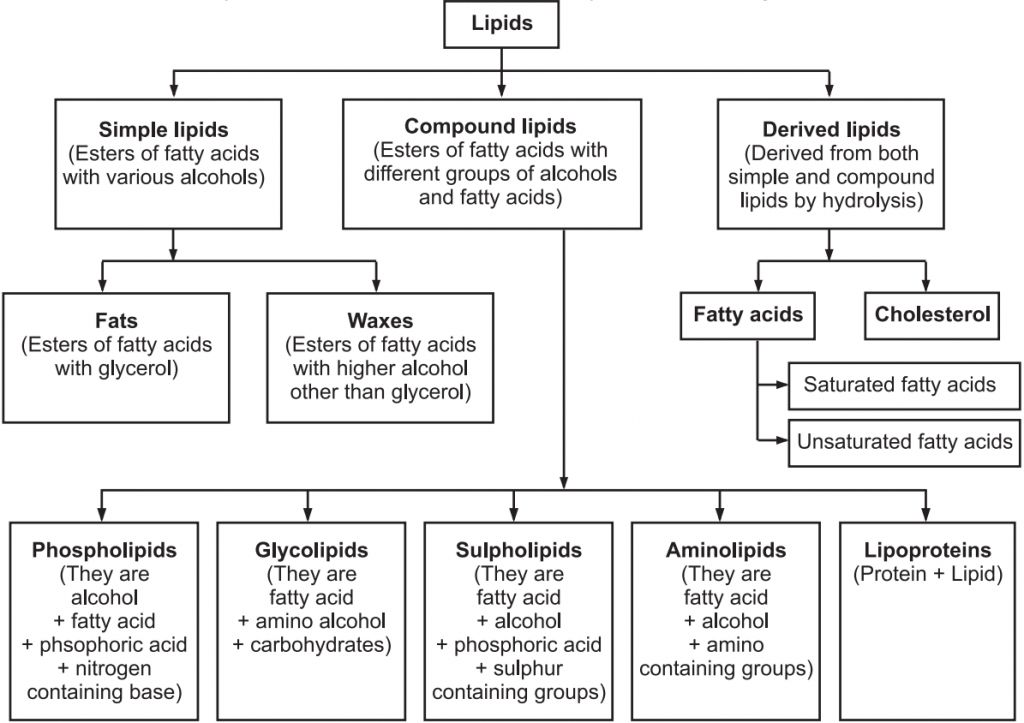
Lipids can be classified as :
1. Simple lipids:
Esters of fatty acids with alcohol.
Simplest alcohol in fats is glycerol (trihydroxypropane).
For example, fats, oils and waxes.
Triglycerides are common in nature.
Fats are esters of fatty acids with glycerol (glycerine).
Each molecule of glycerol can react with three molecules of fatty acids.
Depending on the number of fatty acids that are attached to the glycerol molecule, the esters are called mono-, di-or tri-glycerides.
Fats that are generally liquid at room temperature are called oils.
Oil's are rich in unsaturated fatty acids and consequently have low melting points.
On hydrogenation, the unsaturated fatty acids become saturated and the oil becomes a solid fat ("Vanaspati" and margarine).
(i) Waxes are another class of simple lipids. They are formed by combination of a long-chain fatty acid with a long chain alcohol. Waxes play an important role in protection. They form water-insoluble coatings on hair and skin of animals and stems, leaves and fruits of plants.
(ii) Bees wax is formed from palmitic acid (C16H32O2) and mericyl alcohol (C30H61OH). Bee wax is also called as Hexacosyl palmitate, secreted by worker bees. Lanolin (wool fat), forms a water proof coat around the animal fur.
(iii) Bacteria that cause tuberculosis and leprosy produce a wax (wax-D) that contributes to their pathogenicity.
Cutin is formed by cross esterification and polymerisation of hydroxy fatty acids and other fatty acids without esterification by alcohols other than glycerol. Cuticle has 50 -90% cutin.
Suberin is condensation product of glycerol and phellonic acid. It makes the cell wall impermeable to water.
2. Compound lipids:
These lipids contain an additional group alongwith fatty acids and alcohols e.g. phospholipids, glycolipids, lipoproteins and chromolipids.
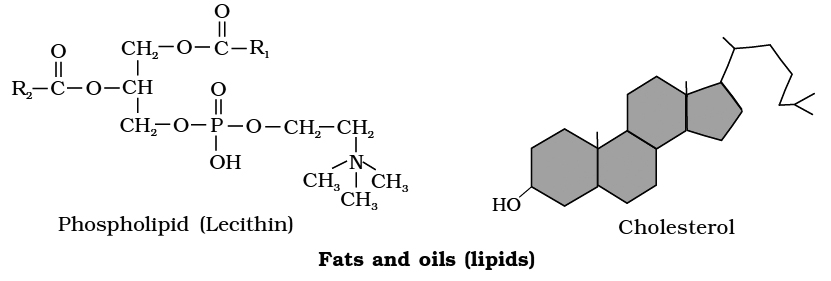
(i) Phospholipids:
These are straight chain compounds of glycerol, fatty acids and phosphoric acid.
In these, only two fatty acids are attached to the glycerol molecule and the third hydroxyl group of glycerol is esterified to phosphoric acid instead of fatty acid.
Depending upon the type of phospholipid, this phosphate is also bound to a second alcohol molecule which can be choline, ethanolamine, inositol or serine.
Common phospholipids are lecithin and cephalin.
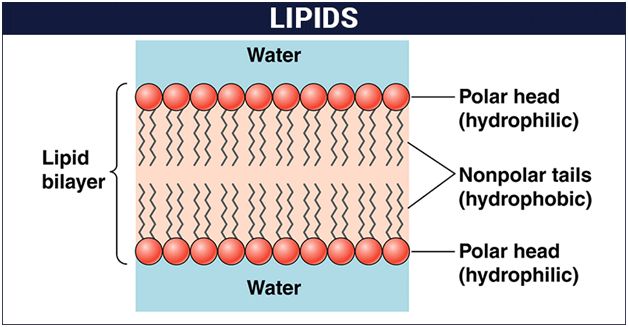
Phospholipids are amphipathic molecules having hydrophilic (water loving) polar region and hydrophobic (water repelling) non-polar regions.
They are the basic constituents of biomembranes.
Many phospholipids arrange themselves in a double layered membrane in aqueous media (lipid bilayer).
Cephalin is found in the brain and acts as insulation material for nerves and also participates in blood coagulation.
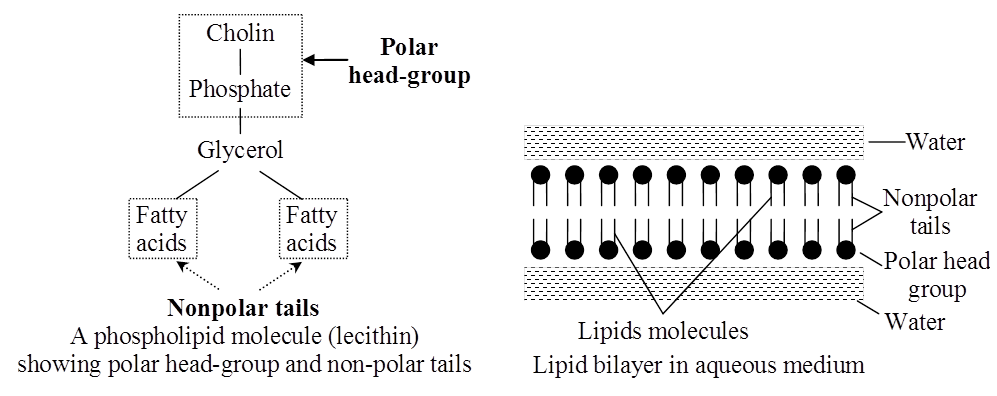
Lecithin takes part in cell permeability, osmotic tension and surface conditioning of cells.
The hydrocarbon chains of the fatty acids are the Non-Polar Tails of the molecule.
The phosphate and the nitrogenous/non-nitrogenous groups form the polar Head-Group of the molecule.
Many phospholipid molecules may arrange themselves in a double-layered membrane (Lipid Bilayer) in aqueous media. These have one or more simple sugars.
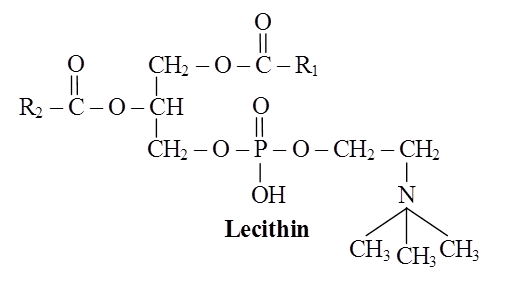
Structure of a phospholipid molecule (R1 and R2 are fatty acids)
(ii) Glycolipids:
They are lipids having sugar residues. Two common glycolipids are cerebrosides and gangliosides.
Composition : Glycolipids contain fatty acids, alcohol sphingosine and sugar such as galactose, glucose etc.
Function : The glycolipids are components of cell membranes, particularly in myelin sheath of nerve fibres and on outer surfaces of nerve cell and in chloroplast membranes.
(iii) Lipoproteins:
Lipoproteins contain lipids (mainly phospholipids) and proteins in their molecules.
Function: Membranes are composed of lipoproteins. Lipids are transported in the blood plasma and lymph as lipoproteins. Lipoproteins occur in the milk and egg yol'k.
(iv) Chromolipids:
These contain pigments such as carotenoids e.g. carotene, vitamin A.
3. Derived lipids –
These are isoprenoid structures e.g. steroids, terpenes, carotenoids, prostaglandins.
(i) Sterols:
Sterols belong to a class of lipids which are not straight chain compounds.
These are composed of fused hydrocarbon rings and a long hydrocarbon side chain.
One of the example is cholesterol.
The cholesterol is found in animals only.
It exists either free or as Cholesterol Ester with a fatty acid.
Cholesterol is also the precursor of hormones such as progesterone, testosterone, estradiol and cortisol.
Another steroid compound, diosgenin produced by the yam plant (Oioscorea) is used in the manufacture of antifertility pills.
(ii) Prostaglandins:
It is a group of hormone-like unsaturated fatty acids which function as messenger substances between cells.
They are derived from arachidonic acid and related C20 fatty acids.
Prostaglandins occur in human seminal fluid menstrual fluid, amniotic fluid and a number of tissues.
They also circulate in blood.
They produce a variety of effects in different organs.
(a) Prostaglandins regulate production of acid in stomach and stimulate contraction of smooth muscles.
(b) They are used to induce labour because they cause uterine contractions.
(c) These can reduce the effect of asthma and gastric acidity. Analgesics like aspirin inhibit prostaglandin synthesis.
(iii) Cholesterol helps in absorption of fatty acids, formation of sex hormones, vitamin D and bile salts. Potato is rich in cholesterol.
(iv) Terpenes are lipid like carbohydrates formed of isoprene units (C5H8)n, e.g., menthol, camphor, carotenoids.
NUCLEOTIDES
(i) This is a group of small complex molecules forming a part of the information transfer system in cells. They are basic units of nucleic acids. They also participate in energy transfer systems
(ii) Nucleotides contain carbon, hydrogen, oxygen, nitrogen and phosphorus.
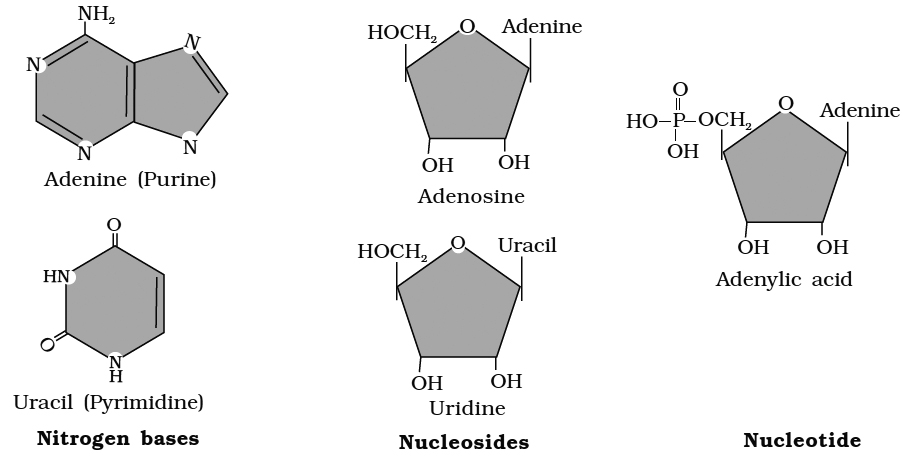
Each nucleotide is made up of a cyclic nitrogenous base, a pentose and one to three phosphate groups.
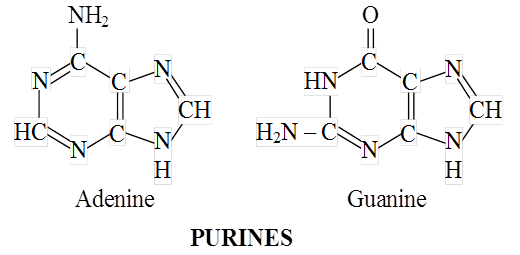
The nitrogenous bases occurring in nucleotides are either a purine or a pyrimidine.
Major purines are adenine and guanine. Thymine, uracil and cytosine are pyrimidines.
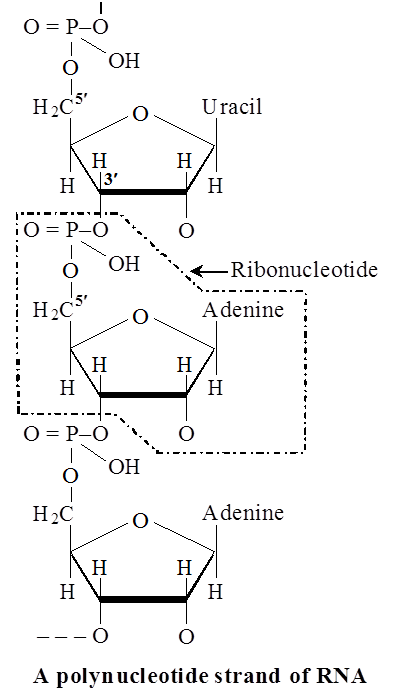
The sugar pentose is either ribose or deoxyribose.
The nucleotides are thus called Ribonucleotides or Deoxyribonucleotides.
Examples of ribonucleotides and deoxyribonucleotides are adenylic acid (AMP) and deoxyadenylic acid (d AMP) repetitively.
Ribonucleotides are the basic units of ribonucleic acids (RNA) and deoxyribonucleotides are basic units of deoxyribonucleic acids (DNA).
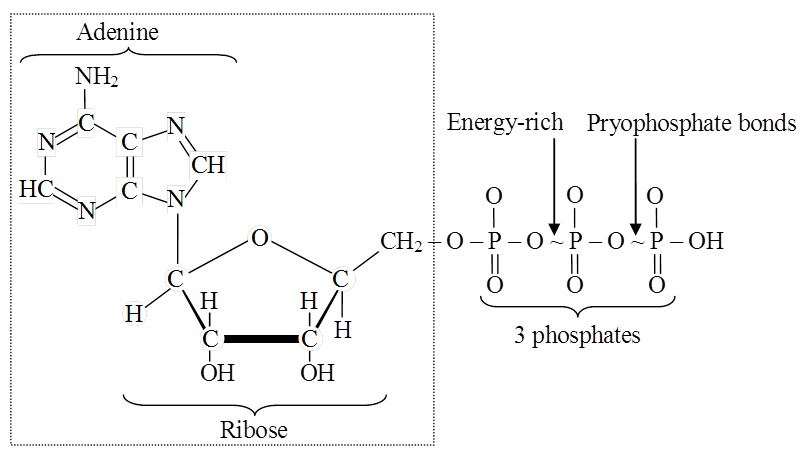
Nucleotides are mono-, di-or tri-phosphate of nucleosides.
For example, adenylic acid or adenosins monophosphate (AMP).
Adenosine disphosphate (ADP) and adenosine triphosphate (ATP) are higher adenine nucleotides.
Nucleotides with more than one phosphate group are called higher nucleotides, e.g., ATP and ADP. likewise, other purines and pyrimidines can also form higher nucleotides.
(iii) Higher nucleotides of purines and pyrimidines occur in the free state, e.g., ATP, ADP. Their third and second phosphate bonds can release about 8 kcal or more of free energy per mol on hydrolysis. This far exceeds the energy released on hydrolysis of most other covalent bonds. Therefore, these phosphate bonds of higher nucleotides are called High-Energy Bonds.
Nucleotides of the vitamins nicotinamide and riboflavin occur either freely or in combination with specific proteins, thus work as coenzymes. They do not participate in the formation of nucleic acids. Instead, they act along with oxidising enzymes and participate in oxidation reactions occurring in the cell.
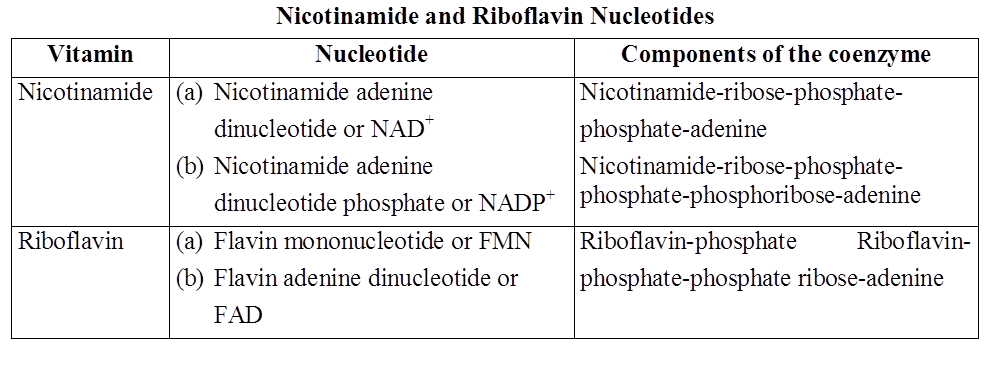
Functions of Nucleotides
Purine and pyrimidine nucleotides polymerise to form nucleic acids.
Higher purine and pyrimidine nucleotides, particularly ATP, store energy in their high-energy phosphate bonds.
They are formed during photosynthesis and respiration.
Hydrolysis of the phosphate bonds of ATP releases their bond energy for driving energy-dependent reactions and processes.
Nicotinamide and riboflavin nucleotides act as coenzymes of oxidising enzymes.
Lipids
Lipids
Lipids are organic molecules containing hydrogen, carbon, and oxygen atoms that provide the structural and functional foundation for living cells. Because water is a polar molecule, these organic compounds are nonpolar molecules that are only soluble in nonpolar solvents and insoluble in water. These molecules are produced in the human liver and can be found in the oil, butter, whole milk, cheese, fried foods, and some red meats.
Structure of Lipids
Lipids are fatty acid polymers with a long, non-polar hydrocarbon chain and a short polar area that contains oxygen.Lipids are often insoluble in water. It's possible that they're just simple fatty acids. A carboxyl group is connected to the R group in a fatty acid. The R group could be methyl (–CH3), ethyl (–C2H5), or a combination of the two (1 carbon to 19 carbons). Palmitic acid, for example, comprises 16 carbons, including the carboxyl carbon. Arachidonic acid, including carboxyl carbon, has 20 carbon atoms.Saturated fatty acids have no double bonds, while unsaturated fatty acids have one or more C=C double bonds. Glycerol, which is trihydroxy propane, is another simple lipid. Glycerol and fatty acids are found in many lipids. The fatty acids are esterified with glycerol. Monoglycerides, diglycerides, and triglycerides are the three types of lipids. Based on their melting point, these are also known as fats and oils. Oils (e.g., gingely oil) have a lower melting point and hence remain as oil in the winter. Phosphorus and a phosphorylated organic molecule are found in some lipids. Phospholipids are what they're called. They're located in the membranes of cells. One example is lecithin. Lipids with more complicated structures are found in some tissues, particularly brain tissues.
Listed below are some important characteristics of Lipids.
1. Lipids are oily or greasy nonpolar molecules, stored in the adipose tissue of the body.
2. Lipids are a heterogeneous group of compounds, mainly composed of hydrocarbon chains.
3. Lipids are energy-rich organic molecules, which provide energy for different life processes.
4. Lipids are a class of compounds characterized by their solubility in nonpolar solvents and insolubility in water.
5. Lipids are significant in biological systems as they form a mechanical barrier dividing a cell from the external environment known as the cell membrane.
Classification of Lipids:
Lipids serve a critical role in our bodies. They are a component of the cell membrane's structure. They aid in the production of hormones and provide energy to our bodies. They aid in appropriate meal digestion and absorption. If we eat them in the right amounts, they constitute a nutritious element of our diet. They play a vital function in signaling as well.
Nucleic Acids
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
NUCLEIC ACIDS
First discovered by Meischer.
Nucleic acids are giant molecules having a variety of functions.
There are two major types of nucleic acids Deoxyribonucleic Acid or DNA and Ribonucleic Acid or RNA.
DNA is found mainly in the nucleus but also occurs in chloroplasts and mitochondria.
It is the genetic material and contains all information needed for the development and existence of an organism.
RNA occurs as genetic material in some viruses.
Nucleic acids are linear polymers of purine and pyrimidine nucleotides.
The nucleotides are linked serially by phosphate groups, each linking the C5(5 – C) and the C'3(3' – C) of the pentoses of the successive nucleotides.
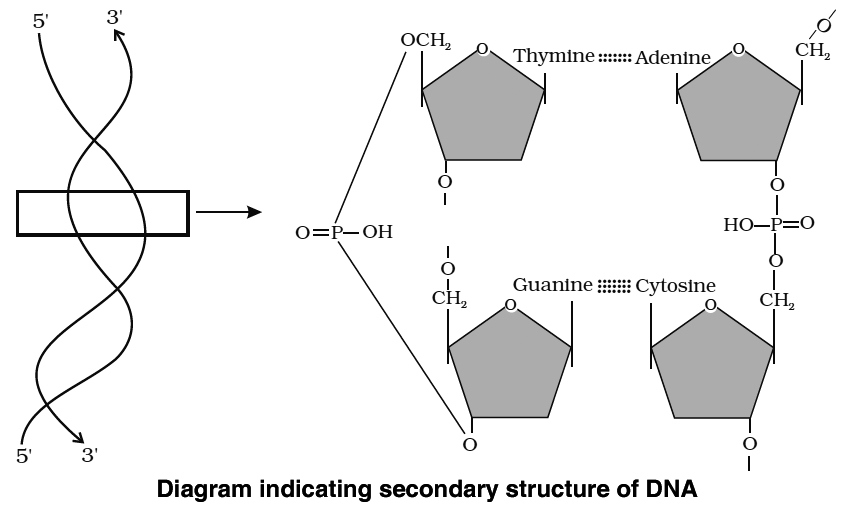
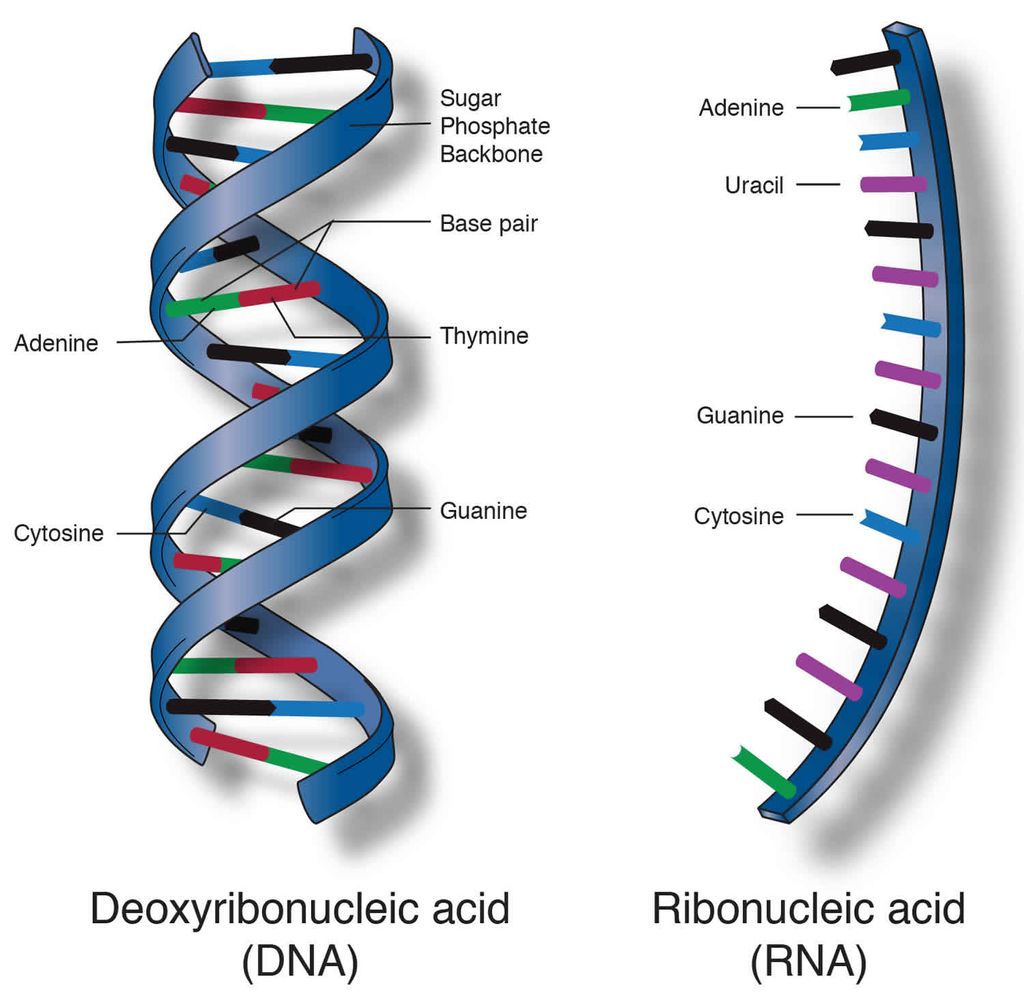
The DNA molecule consists of a double chain of nucleotides, whereas RNA consists of a single chain.
The nucleotides of DNA contain the bases adenine (A), thymine (T), guanine (G) and cytosine (C), while RNA contains A, G, C and uracil (U) instead of T.
The backbone of the nucleic acid is uniformly made up of alternating pentose and phosphate groups.
The pentose in DNA is deoxyribose (CsH10O4) and that in RNA is ribose (C5H10O5).
In the double stranded DNA, the bases of the opposite strands pair in a specific relationship by means of hydrogen bonds.
'A' always pairs with 'T' and 'G' always pairs with 'C'.
This complementarity is known as the Base-Pairing Rule.
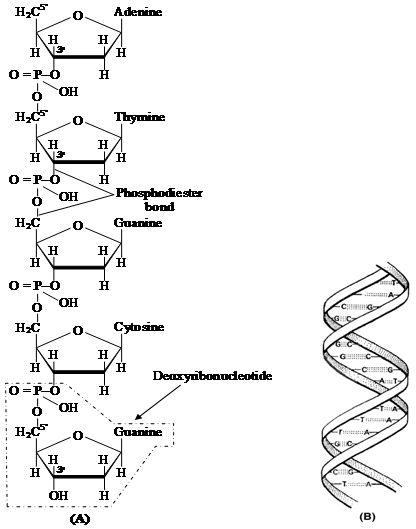
Nucleic acids exhibit a wide variety of secondary structures. For example, one of the secondary structures exhibited by DNA is the famous Watson-Crick model.
This model says that DNA exists as a double helix.
The two strands of polynucleotides are antiparallel i.e. run in the opposite direction.
The backbone is formed by the sugar-phosphatesugar chain.
The nitrogen bases are projected more or less perpendicular to this backbone but face inside.
A and G of one strand compulsorily base pairs with T and C, respectively, on the other strand.
There are two hydrogen bonds between A and T.
There are three hydrogen bonds between G and C.
Each strand appears like a helical staircase.
Each step of ascent is represented by a pair of bases.
At each step of ascent, the strand turns 36°.
One full turn of the helical strand would involve ten steps or ten base pairs.
Attempt drawing a line diagram.
The pitch would be 34 Å.
The rise per base pair would be 3.4 Å.
This form of DNA with the above mentioned salient features is called B-DNA.
In higher classes, you will be told that there are more than a dozen forms of DNA named after English alphabets with unique structural features.
In 1950, Erwin Chargaff found that in any DNA molecule:
(i) The amounts of purines and pyrimidines are equal i.e., A + G = T + C.
(ii) The amount of adenine is always equal to that of thymine; and the amount of guanine is always equal to that of cytosine (i.e., A =T and G =C).
(iii) The base ratio (A + T)/(G + C) may vary from one species to another, but is constant for a given species.
(iv) The deoxyribose sugar and phosphate components occur in equal proportions.
RNA is usually single-stranded, but sometimes (as in Reovirus and Rice dwarf virus), it is double-stranded.
RNA does not follow Chargaff's rules i.e., 1 : 1 ratio does not exist between purines and pyrimidines bases due to single-stranded nature and lack of complementarity.
(B) Watson-Crick model of DNA double helix
There are three types of non-genetic RNA.
(i) Messenger RNA (m-RNA) : It is produced in the nucleus and carries the information for the synthesis of proteins; it was discovered by Jacob and Monod (1961).
(ii) Ribosomal RNA (r-RNA) : It is the largest RNA and constitutes about 80% of total cellular RNA. Found in the ribosomes where protein synthesis takes place.
(iii) Transfer RNA or Soluble RNA or adaptive RNA (s-RNA, t-RNA) : It is the smallest type of RNA and constitutes about 10-15% of total cellular RNA. These are found in the cytoplasm and are different types (as many types as the types of amino acids -usually 20). Their function is to collect amino acids from the cytoplasm for protein synthesis.
t-RNA molecule is folded to form a clover leaf -like structure. This structure was given by Holley.
weight organic compounds in living tissues
Points to Remember
1. Study of X-ray diffraction patterns of DNAs isolated from various organisms by Wilkins, Franklin and Astbury revealed that DNA has a right handed helical structure.
2. Using all the available chemical and physical information, James Watson and F.C. Crick of Cambridge gave the double helix model of DNA for which they were awarded the Nobel Prize in 1962.
3. The width between the two backbones is constant and equal to the width of a base pair (i.e., width of a purine + a pyrimidine).
4. Along the axis of the molecule, the base pairs are 'spaced at intervals of 0.34 nm. Therefore, one complete turn of the double helix comprises 3.4 nm (10 base pairs).
5. There is no restriction on the sequence of bases in one chain. However, due to rule of base pairing, the sequence of one chain determines the sequence in the other. The two chains are thus said to be complementary. As a result, the (purine) adenine in either chain is associated with (pyrimidine) thymine in the other. Similarly, the (purine) guanine in either chain is associated with the (pyrimidine) cytosine in the other.
6. The two chains are held together by hydrogen bonding between the bases (joined together in pairs)-a single base from one chain being hydrogen-bonded to the complementary base from the complementary chain.
7. Adenine-thymine pair has two hydrogen bonds and the guanine–cytosine pair has three hydrogen bonds.
8. The double helix has a diameter of 20Å i.e., the distance between two strands is 19.8Å (or 20Å).
9. DNA with higher percentage of G C have more density than those with higher percentage of A = T.
10. Upon heating at temperatures above 80-90º, the two strands of DNA uncoil and separate (denaturation). On cooling, the strands come closer and are rejoined together (renaturation/ annealing). Low melting area of DNA is A = T base pairs.
11. 1 µm of DNA contains about 3000 base pairs.
12. The DNA is mostly right handed. This type of DNA exists in 4 forms -
(a) B form - the usual DNA, having 10 base pairs per turn.
(b) A form - having 11 base pairs (instead of 10 base pairs per turn), the base pairs are not perpendicular to the axis, but are tilted.
(c) C form - like B form, but having 9 base pairs per turn.
(d) D form - like B form, but have 8 base pairs per turn.
13. DNA with left handed coiling is called Z-DNA. In it, repeating unit is dinucleotide.
14. In some cases, as in × 174 and S-13 viruses, the DNA is single stranded.
Palindromic and repetitive DNA: DNA duplex possessing areas of same sequences of nucleotides is called palindromic DNA. Repetitive DNA has sequence of nitrogen bases repeated several times in tandem.
Nucleic Acids
Nucleic Acids
The nucleic acid is another form of macromolecule found in the acid-insoluble portion of any living tissue. Polynucleotides are a type of nucleotide. They make up the real macromolecular fraction of any living tissue or cell, together with polysaccharides and polypeptides. A nucleotide is the building block of nucleic acids. A nucleotide is made up of three chemically different parts. A heterocyclic molecule is one, a monosaccharide is another, and phosphoric acid or phosphate is the third. The nitrogenous bases adenine, guanine, uracil, cytosine, and thymine are heterocyclic molecules in nucleic acids. The purines Adenine and Guanine are substituted, with the pyrimidines Thymine and Cytosine. Purine and pyrimidine are the components for the skeletal heterocyclic ring.Polynucleotides include either ribose (a monosaccharide pentose) or 2' deoxyribose as a sugar. Deoxyribonucleic acid (DNA) is a nucleic acid that contains deoxyribose, whereas ribonucleic acid (RNA) contains ribose sugar.
Secondary structures in nucleic acids come in a range of shapes and sizes. The famous Watson - Crick Model, for example, is one of DNA's secondary structures. According to this idea, DNA is a double helix. Polynucleotide strands are antiparallel, meaning they run in opposite directions. The sugar-phosphate-sugar chain makes up the backbone. The nitrogen bases are positioned perpendicular to the backbone but on the inside. One strand's A and G must base pair with the other strand's T and C, respectively. Between A and T, there are two hydrogen bonds, while between G and C, there are three hydrogen bonds.
Each thread resembles a spiral staircase. A pair of bases represent each stage of the ascent. The strand rotates 36 degrees with each climbing step. Ten steps or ten base pairs would be required to complete a full turn of the helical strand. It would be a 34 pitch. The increase would be 3.4 per base pair. B-DNA is a type of DNA that has the characteristics listed above. More than a dozen kinds of DNA named after English alphabets with unique structural properties are known to exist.
Concept of Metabolism and living state
Concept of metabolism and living state
Thousands of organic chemicals can be found in living species, whether they be bacteria, protozoa, plants, or animals. These substances or biomolecules exist at specific concentrations (mols/cell, mols/litre, and so on). The discovery that all biomolecules have a turnover was one of the most significant discoveries ever made. This means they're continually changing into and out of different biomolecules. Chemical reactions occur frequently in living organisms, breaking and making this possible. Metabolism refers to the sum of all these chemical events. The change of biomolecules occurs in each of the metabolic processes.
Removal of carbon di oxide from amino acids, resulting in an amine, removal of amino group in a nucleotide base, hydrolysis of a glycosidic bond in a disaccharide, and so on are some examples of metabolic transformations. There are tens of thousands of examples like this. The majority of these metabolic events are always related to other reactions and do not occur in isolation. In other words, metabolites are changed into one another through metabolic pathways, which are a set of related reactions. These metabolic pathways are comparable to city traffic in terms of complexity. There are two types of pathways: linear and circular. There are traffic crossroads where these paths cross one other.Like car traffic, the flow of metabolites through the metabolic pathway has a set rate and direction. The dynamic state of bodily constituents refers to this metabolite flux. What matters most is that this interconnected metabolic traffic runs smoothly and without a single reported hiccup under normal circumstances. Every chemical reaction in these metabolic pathways is a catalysed reaction, which is another distinguishing trait. In biological systems, there is no metabolic conversion that is not catalysed. Even the physical process of CO2 dissolving in water is a catalysed reaction in biological systems. Proteins are also catalysts that speed up the tempo of a metabolic conversation. Enzymes are the name given to these catalytic proteins.
Metabolic basis for living
Metabolic pathways can either lead to a more complex structure from a simpler structure (e.g., acetic acid becomes cholesterol) or a simpler structure from a complex structure (e.g., acetic acid becomes cholesterol) (for example, glucose becomes lactic acid in our skeletal muscle). The former are referred to as biosynthetic or anabolic pathways. The latter are referred to as catabolic pathways since they involve degradation. Anabolic pathways, use a lot of energy. Energy is required to assemble a protein from amino acids. Catabolic pathways, on the other hand, result in the release of energy. When glucose is metabolized to lactic acid in skeletal muscles, for example, energy is released. Glycolysis is a metabolic mechanism that takes glucose and converts it to lactic acid in ten stages.
Living organisms have figured out how to capture the energy released during breakdown and store it as chemical bonds. This bond energy is used as needed for biosynthetic, osmotic, and mechanical tasks that we do. The bond energy in a molecule called adenosine triphosphate is the most essential kind of energy currency in living systems (ATP).
The living state
Tens and thousands of chemical compounds in a living organism, otherwise called metabolites, or biomolecules, are present at concentrations characteristic of each of them. For example, the blood concentration of glucose in a normal healthy individual is 4.5-5.0 mM. The most important fact of biological systems is that all living organisms exist in a steady-state characterized by concentrations of each of these biomolecules. These biomolecules are in metabolic flux. Any chemical or physical process moves spontaneously to equilibrium. The steady state is a non-equilibrium state. One should remember from physics that systems at equilibrium cannot perform work. As living organisms work continuously, they cannot afford to reach equilibrium.
Thus, to be able to conduct work, the living state is a non-equilibrium steady-state; the living process is a constant endeavour to avoid slipping into equilibrium. This is accomplished by the use of energy. Metabolism is the process by which energy is produced. As a result, the terms "living state" and "metabolism" are interchangeable. There can be no living condition without metabolism.
Enzymes
- Books Name
- ACME SMART COACHING Biology Book
- Publication
- ACME SMART PUBLICATION
- Course
- CBSE Class 11
- Subject
- Biology
ENZYMES
Enzymes are proteinaceous, biocatalysts.
First enzyme discovered by Buchner.
Term enzyme was given by Kuhne.
Zymase (from yeast) was the first discovered enzyme. (Buchner)
The first purified and crystalized enzyme was urease (by J.B. Sumner) from Canavalia/Jack Bean (Lobia plant).
Proteinaceous nature of enzyme was established by Northrop and Sumner.
DEFINITION
Enzymes are biocatalysts made up of proteins (except ribozyme), which increases the rate of biochemical reactions by lowering down the activation energy.
First discovered ribozyme was L19 RNAase by T.Cech from rRNA of a protozoan Tetrahymena thermophila and RNAase P or Ribionuclease P by Altman in prokaryotic cell (Nobel prize).
GENERAL PROPERTIES OF ENZYMES
Large sized biomolecules, colloid nature with high molecular weight.
Large size (equal to colloid particles) provide, more surface area so passes large no. of active site. Large number of substrate converted into product by one molecule of enzyme at a time.
Highest molecular weight is of enzyme pyruvate dehydrogenase complex (46 lakh) participate in link reaction of respiration.
Proteinous nature
Monomer unit of a enzyme is Amino acid.
Amino acids linked togather to form polypeptide chain.
Enzymes are polypeptide chains.
Most of enzymes arrange in tertiary structure of protein or globular proteins except isoenzyme (Quaternary st.).
Tertiary structure of protein provides stability and water soluble nature to enzymes.
Synthesis of enzymes occurs on ribosomes under the control of genes.
According to one gene one polypeptide hypothesis, if a enzyme is made up of same kind of polypeptide chains then synthesize under control of same gene and if made up of different kinds of polypeptide chains then synthesized under the control of different genes. e.g., Rubisco, cytochrome, oxidase, Nitrogenase.
Specificity
Enzymes are specific for pH, temperature and substrate.
pH - The common pH range of enzymes activity is 6 - 8.
Every enzyme works on specific pH, Pepsin-2.5 pH, Hydrolase-4-5.
Rubisco, Pepcase-8.5 pH, Trypsin - 8.5 pH.
Temperature
Common range of temperature for enzyme activity is 20º – 40°C.
Enzymes works on body temperature of organism not on environmental temperature.
Enzymes of plants are affected by evironmental temperature change as plants does not show homeostasis.
At low temperature enzymes become functionally inactive, at high temperature denatured.
Substrate
Every enzyme works on specific substrate.
Substrate binds at active site of enzyme which is made of specific sequence of amino acids and recognise it’s substrate.
Ex. succinic dehydrogenase acts on succinic acid while pyruvate dehydrogenase acts on pyruvic acid.
Enzymes increase the rate of reaction by decreasing activation energy.
Activation Energy - Minimum amount of energy more than the free energy of reactents required to reach the transiation state of chemical reaction or to undergo the chemical reaction.
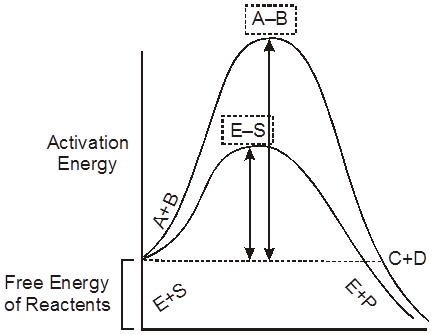
Turn Over Nubmer (T.O.N.) -
The number of reactent moleules converted into product by one molecule of enzyme in unit time
Highest T.O.N is of carbonic anhydrase (360 lakh / minute)
CO2 + H2O  H2CO3
H2CO3
KM constant -
Enymes follows the Michaelis-Menten reaction kinetics.
It represents the substrate concentration at which rate of enzymetic reaction becomes the half of maximum velocity or rate.
If a enzyme passes high km constant then it’s affinity towards substrate is low and rate reaction is also low.
The energy required for a chemical reaction to proceed is called Activation energy.
The enzymes lower the activation energy. (Remember that enzymes cannot start the chemical reaction)
With the increase in concentration of substrate the enzymatic velocity also increases. At a certain value all the active site of the enzyme-molecules are saturated and the increase in substrate concentration does not increase the velocity of the enzymatic reaction.
(The concentration of substrate at which the velocity of enzymatic action reaches half of its maximum value, is called Km value or Michaelis constant).
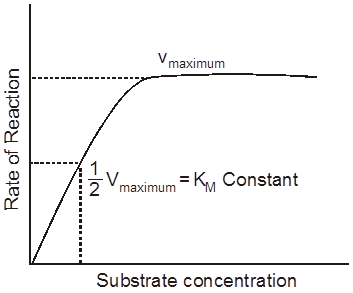
Higher is the affinity of an enzyme for a substrate the lower is its Km value, i.e.
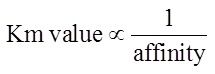
Ki constant (Enzyme inhibitor complex dissociation constant)
The substrate concentration at which enzyme inhibitor complex dissociate and reaction becomes normal
It is applicable only for competitive reversible inhibitions.
STRUCTURE OF ENZYME
Simple enzymes
They are made up of only protein. eg. pepsin, trypsin.
Conjugated enzymes
They are made up of protein & non protein part.
Co-enzymes - Co-enzymes are non-protein, orgainc groups, which are loosely attached to apoenzymes. They are generally made up to vitamins.
Prosthetic group - When non-protein part is tightly or firmly attached to apoenzymes.
Metal activators/co-factros/metallic factor :- Lossely attached inorganic co-factor eg. Mn, Fe, Co, Zn, Ca, Mg, Cu
Active site :
The part of polypeptide chain made up of specific sequence of amino acids at which specific substrate is to be binded and catalysed, known as active site. Very specific sequence of amino acids, at active site is determined by genetic codes.
Allosteric site :
Besides the active site's some enzymes posess additional sites, at which chemical other than substrate (allosteric modulators) are bind. These sites are known as allosteric sites and enzyme with allosteric sites are called as allosteric enzymes. e.g. hexokinase, phosphofructokinase.
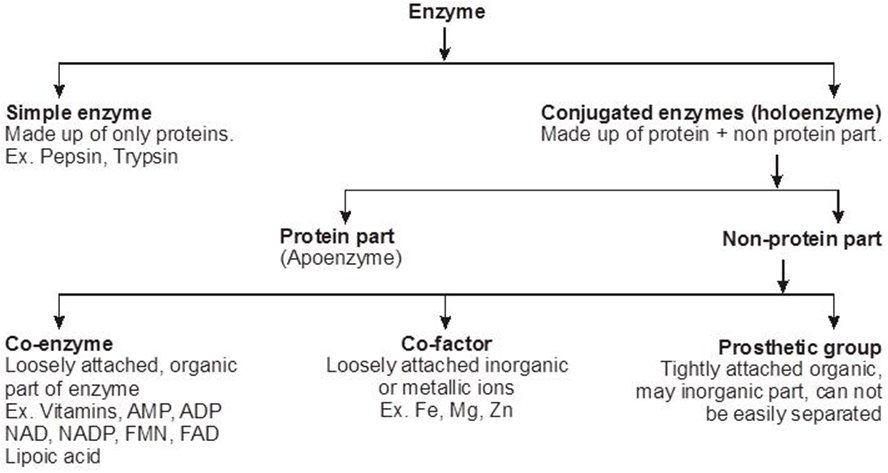
Concept Builder
TERMINOLOGY
Endoenzymes - Enzymes which are functional only inside the cells. Ex. Enzymes of metabolism.
Exoenzymes - Enzymes catalysed the reactions outside the cell Eg:- enzymes of digestion, some enzymes of insectivorous plants, Zymase complex of fermentation.
Proenzyme/Zymogen - These are precursor of enzymes or inactive forms of enzymes.eg. Pepsinogen, Trypsinogen etc.
Isoenzymes - Enzymes having similar action, but little difference in their molecular configuration are called isoenzymes. 16 forms of -amylase of wheat & 5 forms of LDH (Lactate dehydrogenase) 3 Forms of Pepcase are known. These all isoenzyme forms are synthesised by different genes and tissue and organ specific.
Inducible enzymes - When formation of enzyme is induced by substrate availability. e.g. Lactase, Nitrogenase, -galactosidase.
Extremozymes - Enzymes, which may also function at extremely adverse conditions (very high temperature) e.g. Taq polymerase.
Abzymes - When the monoclonal antibodies (Mab) are used as enzymes.
Biodetergents - Enzymes used in washing powders are known as bio-detergents e. g.-amylase, lipase, proteolytic enzymes.
House keeping/constitutive enzymes - Which are always present in constant amount & are also essential to cell. Ex. Enzymes of cell respiration.
Concept Builder
Metal ion Metalloenzyme
Fe++, Fe+++ Cytochrome oxidase, catalase, aconitase, peroxidase
Ca++ Lipase, Succinic dehydrogenase, thrombin, thrombokinase
Mg++ Hexokinase, pyruvate kinase, DNA Polymerase, enolase, phosphotransferase
Cu++ Cytochrome oxidase, tyrosinase
Co++ Ascorbic acid oxidase, Peptidases
Mo Dinitrogenase, nitrate reductase
Mn++ Ribouncieotide reductase, Arginase
Zn++ Alcohol dehydrogenase, Carbonic anydrase, LDH, carboxypeptidase,
Glycine reductase, thiolase
Se Glycine reductase, thiolase
K+ Pyruvate kinase
Ni Urease
Cl– Salivary amylase
Na+ ATPase
Classification of Enzymes
Enzymes were variously named in the past.
Enzyme names such as ptyalin (salivary amylase), pepsin and trypsin, give no indication of their action.
Other enzymes such as amylase, sucrase, protease and lipase were named after the substrates on which they act-amylose (starch), sucrose, protein and lipids respectively.
Still others were named according to the source from which they were obtained-papain from papaya, bromelain from pineapple (belongs to the family Bromeliaceae).
Some like DNA polymerase indicate its specific action, polymerisation.
The Duclaux (1883) provided a system for naming enzymes by adding suffix -ase at the end of enzyme name.
In this system, each enzyme ends with an -ase and consists of two parts, the first part indicates its substrate and the second the reaction catalysed.
For example, glutamate pyruvate transaminase transfers an amino group from the substrate glutamate to another substrate pyruvate.
However, arbitrary names like ptyalin and trypsin still continue to be used because of their familiarity.
Enzymes are grouped into six major classes:
Class 1. Oxidoreductases:
These catalyse oxidation or reduction of their substrates and act by removing or adding electrons (and/or H+) from or to substrates e.g., cytochrome oxidase oxidises cytochrome.
Class 2. Transferases:
These transfer specific groups from one substrate to another. The chemical group transferred in the process is not in a free state, e.g., glutamate pyruvate transaminase.
Class 3. Hydrolases:
These break down large molecules into smaller ones by the introduction of water (hydrolysis) and breaking of specific covalent bonds. Most digestive enzymes belong to this category, e.g., amylase which hydrolyses starch, lipases.
Class 4. Lyases:
These catalyse the cleavage of specific covalent bonds and removal of groups without hydrolysis, e.g., histidine decarboxylase cleaves C-C bond in histidine to form carbon dioxide and histamine.
Class 5. Isomerases:
These catalyse the rearrangement of molecular structure to form isomers, e.g., phosphohexose isomerase changes glucose-6-phosphate to fructose-6-phosphate (both are hexose phosphates).
Class 6. Ligases:
These catalyse covalent bonding of two substrates to form a large molecule. The energy for the reaction is derived from the hydrolysis of ATP. Pyruvate carboxylase combines pyruvate and carbon dioxide to form oxaloacetate at the expense of ATP.
Factors Affecting Enzyme Activity
Tile activity of an enzyme can be affected by a change in the conditions which can alter the tertiary structure of the protein.
These include temperature, pH, change in substrate concentration or binding of specific chemicals that regulate its activity.
Temperature and pH
Enzymes generally function in a narrow range of temperature and pH (in figure).
Each enzyme shows its highest activity at a particular temperature and pH called the optimum temperature and optimum pH.
Activity declines both below and above the optimum value.
Low temperature preserves the enzyme in a temporarily inactive state, whereas high temperature destroys enzymatic activity because proteins are denatured by heat.
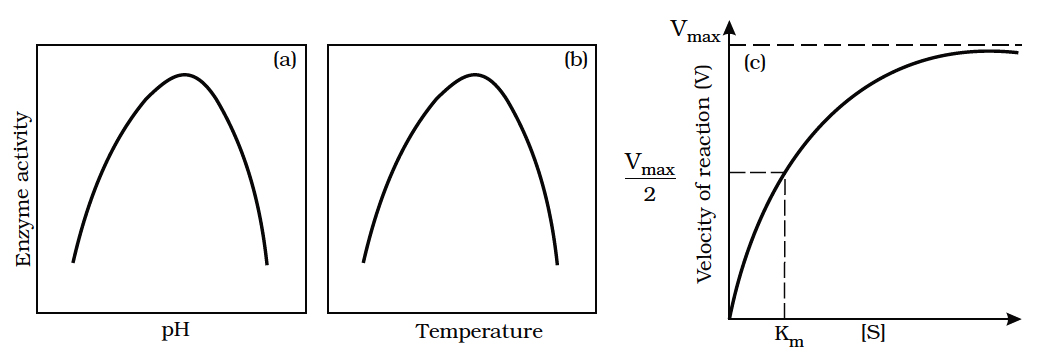
Effect of change in : (a) pH, (b) Temperature and
(c) Concentration of substrate on enzyme activity
(i) Optimum Temperature:
Enzymes generally work over a narrow range of temperatures.
Usually it corresponds to the body temperature of the organism.
For instance, human enzymes work at the normal body temperature.
Each enzyme shows its highest activity at a particular temperature called the optimum temperature.
Activity declines both above and below the optimum temperature.
Temperature:
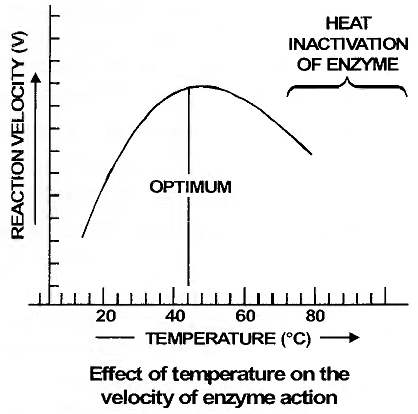
Every enzyme has a specific optimum temperature.
According to the general rule of thumb the Q10 (temperature coefficient) for enzymes is 2-3, i.e., in between minimum and optimum temperature (5-40°C), the rate of reaction increases 2-3 times with rise in 10°C temperature.
If temperature is reduced to near or below freezing point, the enzymes are inactivated (not denatured).
Most enzymes show maximum activity in a temperature range of 25-40°C.
Enzymes are thermolabile i.e., are denatured at high temperature.
The loss of catalytic properties begins at 35ºC and is almost complete around 60°C.
However, dried enzyme extracts can endure temperature of 100°C-120°C or even higher.
That is why, dry seeds can endure higher temperature than germinating seeds.
Thermal stability is thus an important quality of some enzymes isolated from thermophilic organisms.
(ii) Optimum pH :
Each enzyme shows its highest activity at a specific pH.
This is called the optimum pH.
Activity declines both above and below the optimum pH.
Most intracellular enzymes function best around neutral pH.
Some digestive enzymes have their optimum in the acidic or alkaline range.
For example, the protein digesting enzyme pepsin found in the stomach, has an optimum pH of 2.0.
Another protein-digesting enzyme, trypsin, found in the duodenum, functions best in an alkaline pH 8.0.
(iii) Concentration of Substrate:
With the increase in substrate concentration, the velocity of the enzymatic reaction rises at first.
The reaction ultimately reaches a maximum velocity (Vmax) which is not exceeded by any further rise in concentration of the substrate.
This is because the enzyme molecules are fewer than the substrate molecules and after saturation of these molecules, there are no free enzyme molecules to, bind with the additional substrate molecules.
Characteristics of Enzymes
1. Proteinaceous nature: All enzymes are chemically made up of proteins (except ribozyme and ribonuclease-P). They, however may have additional inorganic or organic substances for their activity.
2. Amphoteric nature: The enzymes are capable of ionizing either as an acid or as a base depending upon the acidity of the external solution. Hence, their nature is amphoteric i.e., they can act as acid as well as base.
3. Colloidal nature: They are colloidal in nature due to which they present a large surface area for reaction to take place. They are hydrophilic and form hydrosol in the cell.
4. Reversibility: Like a true catalyst enzymes have been found to accelerate the chemical reaction in either direction i.e., forward and backward depending upon the availability of suitable energy requirement, pH, concentration of end products and availability ot reactants.

5. Molecular weight: Enzymatic proteins are substances of high molecular weight. Peroxidase, which is one of the smallest enzymes, has a molecular. weight of 40,000 whereas catalase, one of the largest enzymes, has a molecular weight of 250,000 (Urease 483,000).
6. Specificity of enzyme: Enzymes are highly specific in nature i.e. , a particular enzyme can catalyze only a particular type of reaction e.g., the enzyme malic dehydrogenase removes hydrogen atom from malic acid and not from other keto acids. The specificity of enzyme is determined by sequence of amino acids in the active sites. The active site possesses a particular binding site which complexes only with specific substrate. Thus a suitable substrate fulfils the requirements of active site and closely fixes with it.
7. Unchanged form: Enzymes are in no way transformed or used up in the chemical reaction but come out unchanged at the end of reaction.
8. Chemical reaction: Enzymes do not start a chemical reaction but increase the rate of chemical reaction. They do not change the equilibrium as well. However, they increase the rate of chemical reaction and bring about equilibrium very soon. Carbonic anhydrase is the fastest acting enzyme.

In absence of any enzyme this reaction is very slow, with about 200 molecules of H2C03 being formed in an hour. However, by using the enzyme present within the cytoplasm called carbonic anhydrase, the reaction speeds dramatically with about 600,000 molecules being formed every second. Hence, the enzyme accelerates the reaction rate by about 10 million times.
9. Efficiency: Efficiency of an enzyme is judged by its 'turn over number' i.e., number of substrate molecules changed per minute by a molecule of enzyme. It depends upon the number of active sites present over an enzyme, precise collisions between reactants and the rate of removal of end products The optimum turn-over number for enzyme carbonic anhydrase is 36 million, catalase 5 million, sucrase or invertase 10,000 and flavoprotein 50.
How Enzymes Speed Up Reactions?
A certain amount of energy is necessary to initiate any chemical reaction.
This is called activation energy or free energy of activation.
In a population of molecules of each substrate, the majority have average kinetic energy, some have higher and some lower than the average energy.
Under normal temperature, only the molecules having relatively high energy are likely to react to form the product.
Therefore, the reaction takes place very slowly.
One way to make the reaction go faster is to raise the temperature of the mixture.
Heat increases the kinetic energy of the molecules, causing their collisions and reaction.
The other method of quickening the reaction is by adding an enzyme.
The enzyme lowers the activation energy of the reaction and allows a large number of molecules to react at time.
Exactly how the enzymes lower the activation energy is not clear.
However, it is known that the enzymes combine with the substrate molecules and bring them close together which favours their collisions in the most suitable directions and locations for the reaction to occur.
The inorganic catalysts work in the same manner.
It is now held that conformational changes in the active sites of the enzymes actually "push" the substrate molecules toward an interaction.
Hydrolysis of starch into glucose is an organic chemical reaction.
Rate of a physical or chemical process refers to the amount of product formed per unit time.
Rate can also be called velocity if the direction is specified for a given reaction.
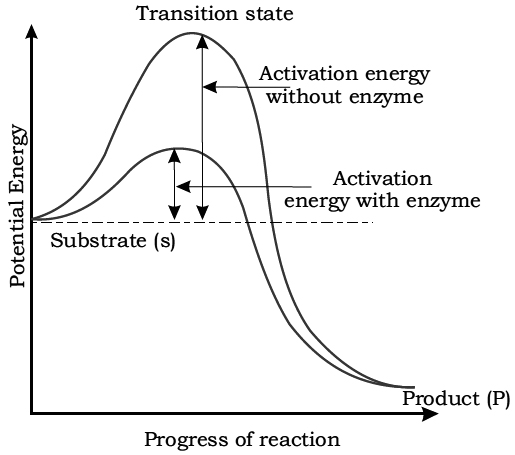
Activation energy requirement of uncatalysed and enzyme-catalysed reactions.
Reactants absorb energy from surroundings to climb the hill of activation energy (EA) and reach the unstable, short lived, transition state. Enzyme speeds up the reaction by reducing the uphill climb to the transition state. In transition state, the reactants are in an unstable condition and reaction can occur.
Concept Builder
1. Some laundry detergents contain enzymes. Generally proteases and amylases are added in detergents used for washing clothes and amylase in detergents used for dish washing. They help to break down proteins and other substances from food that may stain clothing.
2. Dairy digestive supplements contain lactase.
3. Baby foods: Trypsin is added to partially pre-digest the food.
4. Onions: Onions contain sulfur compounds called amino acid sulfoxides which result in the flow of lacrimal fluid.
Mode of Enzyme Action
1. Lock and key Hypothesis was put forward by Emil Fischer in 1894.
2. Induced Fit Theory was proposed by Koshland in 1959. According to this theory the active site of the enzyme contains two groups, buttressing and catalytic. The buttressing group is meant for supporting the substrate.
Mechanism of Enzyme Action
Two hypothesis have been put forward to explain the mode of enzyme action.
1. Lock and Key Hypothesis:
This hypothesis was given by Emil Fischer (1894).
According to this hypothesis, both enzyme and substrate molecules have specific geometrical shapes.
It is similar to the system of lock and key, which have special geometrical shapes in the region of their activity.
The active sites contain special groups having -NH2, -COOH, -SH for establishing contact with the substrate molecules.
Just as a lock can be opened by its specific key, a substrate molecule can be acted upon by a particular enzyme.
This also explains the specificity of enzyme action.
After coming in contact with the active site of the enzyme, the substrate molecules or reactants form a complex called enzymesubstrate complex.
In the enzyme substrate complex, the molecules of the substrate undergo chemical change and form products.
The product no longer fits into the active site and escapes in surrounding medium, leaving the active site free to receive more substrate molecules.
This theory explains how a small concentration of enzyme can act upon a large amount of the substrate.
It also explains how the enzyme remains unaffected at the end of chemical reaction.
The theory explains how a substance having a structure similar to the substrate can work as competitive inhibitor.
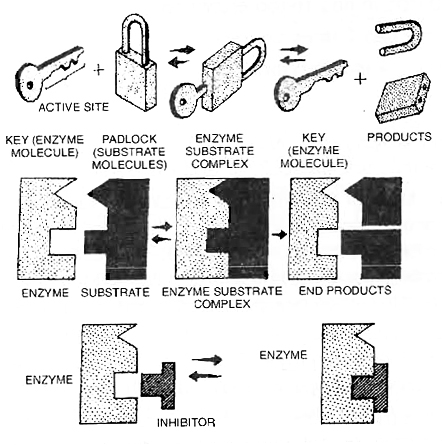
Lock and key hypothesis to show the specificity of enzymes
Enzyme + Substrate  Enzyme — Substrate Complex
Enzyme — Substrate Complex
Enzyme — Substrate Complex  Enzyme + End Products
Enzyme + End Products
2. Induced Fit Hypothesis:
This hypothesis was proposed by Koshland (1960).
According to this hypothesis the active site of the enzyme does not initially exist in a shape that is complementary to the substrate but is induced to assume the complementary shape as the substrate becomes bound to the enzyme.
According to Koshland, "the active site is induced to assume a complementary shape in much the same way as a hand induces a change in the shape of a glove."
An active site of an enzyme is a crevice or a pocket into which the substrate fits.
Thus, enzymes through their active site, catalyse reactions at a high rate.
Hence, according to this model, the enzyme (or its active site) is flexible.
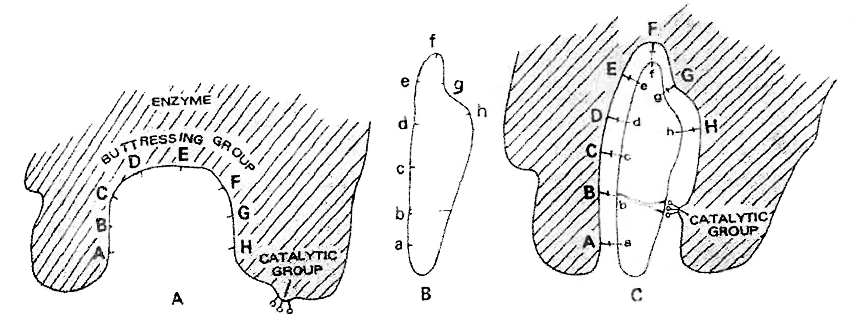
Induced-fit theory of enzyme action. A. active site of enzyme. B. substrate molecule.
C. Enzyme-substrate complex with conformational changes so as to bring the
catalytic group against the substrate bonds to be broken
The active site of the enzyme contains two groups-
(a) Buttressing group is meant for supporting the substrate.
(b) Catalytic group is meant for catalysing the reaction.
When substrate comes in contact with the buttressing group, the active site changes to bring the catalytic group opposite the substrate bonds to be broken.
Iso-enzymes
Multiple molecular forms of an enzyme (synthesized by different genes) occurring in the same organism and having a similar substrate activity. Over 100 enzymes are known to have iso-enzymes such as
(i) -amylase of wheat endosperm has 16-iso-enzymes.
(ii) Lactic acid dehydrogenase has 5 iso-enzymes.
(iii) Alcohol dehydrogenase has 4 iso-enzymes.
Site of Enzyme Action
All enzymes are produced in the living cells.
About 2,000 enzymes have been recorded.
These are of two types with regard to the site where they act: intracellular and extracellular.
1. Intracellular Enzymes:
Most of the enzymes remain and function inside the cells.
They are called the intracellular enzymes or endoenzymes.
Some are dissolved in the cytoplasmic matrix.
A water extract of ground up liver cells contains all the eleven enzymes necessary to change glucose to lactic aid.
Certain enzymes are bound to particles, such as ribosomes, mitochondria and chloroplast.
The respiratory enzymes needed to convert lactic acid to carbon dioxide and water are found in the mitochondria.
2. Extraceliular Enzymes:
Certain enzymes leave the cells and function outside them.
They are called the extracellular enzymes or exoenzymes.
They mainly include the digestive enzymes, e.g., salivary amylase, gastric pepsin, pancreatic lipase; secreted by the cells of the salivary glands, gastric glands and pancreas, respectively.
Lysozyme present in tears and nasal secretion is also an exoenzyme.
The enzymes retain their catalytic action even after extraction from the cells.
Rennet tablets, containing the enzyme rennin from the calf's stomach, are used to coagulate milk protein caseinogen for cheese (casein) formation.
Inhibition of Enzyme Action
The activity of an enzyme is also sensitive to the presence of specific chemicals that bind to the enzyme.
When the binding of the chemical shuts off enzyme activity, the process is called inhibition and the chemical is called an inhibitor.
Following types of enzyme inhibition can occur :
(i) Competitive Inhibition
The action of an enzyme may be reduced or inhibited in the presence of a substance that closely resembles the substrate in molecular structure.
Such an inhibitor is called a Competitive Inhibitor of that enzyme.
Due to its close structural similarity with the substrate, the inhibitor competes with the latter for the substratebinding site of the enzyme.
Consequently, the enzyme cannot participate in catalysing the change of the substrate.
As a result the enzyme action declines, e.g., the inhibition of succinic dehydrogenase by malonate, which closely resembles succinate in structure.
This may be compared to a lock jammed by a key similar to the original key.
Such competitive inhibitors are often used in the control of bacterial pathogens.
For instance, sulpha drugs are competitive inhibitors of folic acid synthesis in bacteria as they substitute for p-amino benzoic acid, thus preventing the next step in the synthesis.
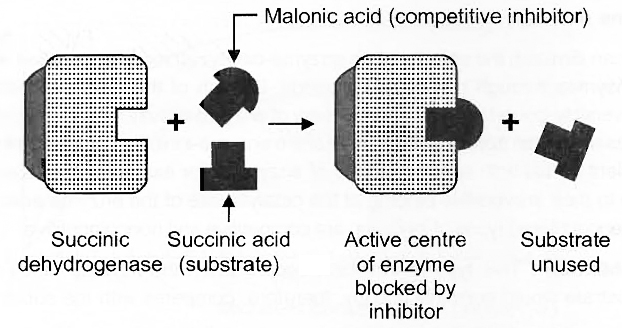
Competitive inhibition of enzyme action
(ii) Non-competitive Inhibition
Cyanide kills an animal by inhibiting cytochrome oxidase, a mitochondrial enzyme essential for cellular respiration.
This is an example of non-competitive inhibition of an enzyme.
Here the inhibitor (cyanide) has no structural similarity with the substrate (cytochrome c) and does not bind with the substrate-binding site but at some other site of the enzyme.
Thus, in non-competitive inhibition, substrate binding takes place but no products are formed.
(iii) Allosteric Modulation or Feedback Inhibition
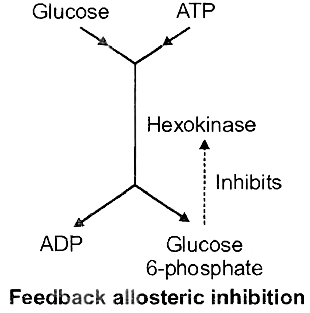
The activities of some enzymes, particularly those which form a part of a chain of reactions (metabolic pathway), are regulated internally.
Some specific low molecular weight substance, such as the product(s) of another enzyme further on in the chain, acts as the inhibitor.
Such a modulator substance binds with a specific site of the enzyme different from its substrate-binding site.
This binding increases or decreases the enzyme action. Such enzymes are called Allosteric Enzymes.
Examples :
(a) Hexokinase which changes glucose to glucose-6-phosphate in glycolysis. Decline in enzyme activity by the allosteric effect of the product is called Feedback Inhibition, e.g., allosteric inhibition of hexokinase by glucose-6-phosphate.
(b) Enzyme phosphofructokinase is activated by ADP and inhibited by ATP.
(c) Another example is inhibition of threonine deaminase by isoleucine. Amino acid isoleucine is formed in bacterium Escherichia coli in a 5-step reaction from threonine. When isoleucine accumulates beyond a threshold value, its further production stops.
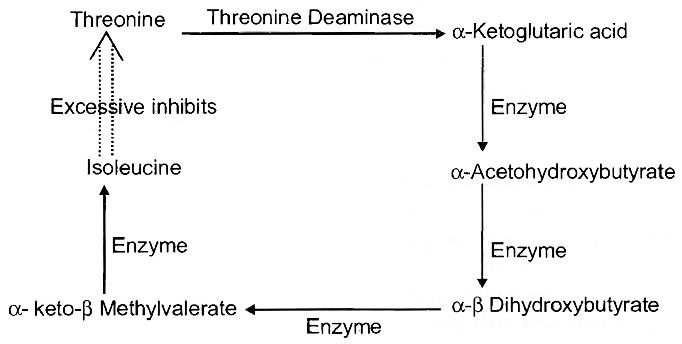
Inhibition of Enzyme Activity
Any substance that can diminish the velocity of an enzyme-catalyzed reaction is called an inhibitor.
Reversible inhibitors bind to enzymes through non-covalent bonds.
Dilution of the enzyme-inhibitor complex results in dissociation of the reversibly-bound inhibitor and recovery of enzyme activity.
Irreversible inhibition occurs when an inhibited enzyme does not regain activity upon dilution of the enzyme-inhibitor complex.
Some irreversible inhibitors act by forming covalent bonds with specific groups of enzymes; for example, the neurotoxic effects of certain insecticides are due to their irreversible binding at the catalytic site of the enzyme acetylcholinesterase.
The two most commonly encountered types of inhibition are competitive and noncompetitive.
A. Competitive inhibition :
This type of inhibition occurs when the inhibitor binds reversibly to the same site that the substrate would normally occupy, therefore, competes with the substrate for that site.
1. Effect on Vmax: The effect of a competitive inhibitor is reversed by increasing [S]. At a sufficiently high substrate concentration, the reaction velocity reaches the Vmax observed in the absence of inhibitor.
2. Effect on Km : A competitive inhibitor increases the apparent Km for a given substrate. This means that in the presence of a competitive inhibitor more substrate is needed to achieve 1/2 Vmax, e.g., sulpha drugs for folic acid synthesis in bacteria and inhibition of succinic dehydrogenase by Malonate.
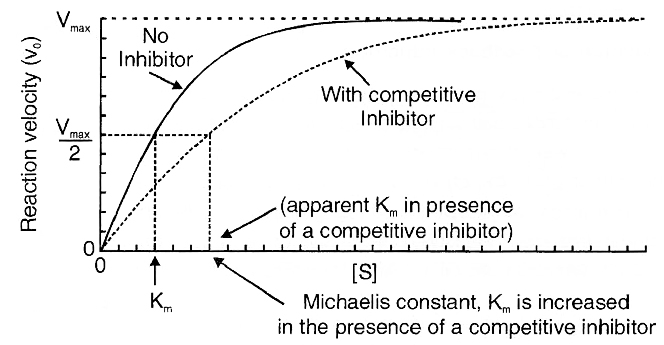
Effect of a competitive inhibitor on the reaction
velocity (v0) versus substrate [S] plot.
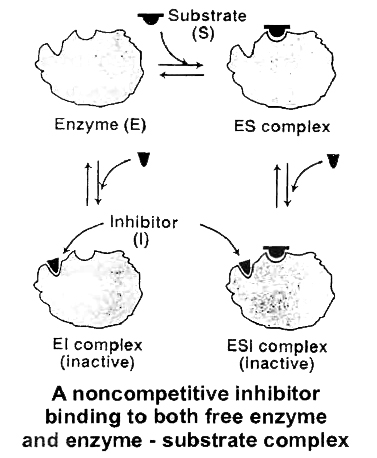
B. Non-competitive inhibition:
This type of inhibition is recognized by its characteristic effect on Vmax. Noncompetitive inhibition occurs when the inhibitor and substrate bind at different sites on the enzyme. The noncompetitive inhibitor can bind either free enzyme or the ES complex, thereby preventing the reaction from occurring.
1. Effect on Vmax : Noncompetitive inhibition cannot be overcome by increasing the concentration of substrate. Thus, noncompetitive inhibitors decrease the Vmax of the reaction.
2. Effect on Km : Noncompetitive inhibitors do not interfere with the binding of substrate to enzyme. Thus, the enzyme shows the same Km in the presence or absence of the noncompetitive inhibitor. e.g., cyanide kills an animal by inhibiting cytochrome oxidase.
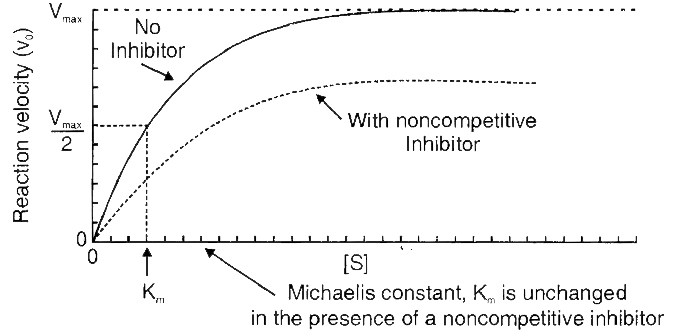
Effect of a noncompetitive inhibitor on the reaction
velocity (v0) versus substrate [S] plot.
Summary
Although there is a bewildering diversity of living organisms, their chemical composition and metabolic reactions appear to be remarkably similar.
The elemental composition of living tissues and non-living matter appears to be similar when analysed qualitatively.
However, a closer examination reveals that the relative abundance of carbon, hydrogen and oxygen is higher in living systems when compared to inanimate matter.
The most abundant chemical in living organisms is water.
There are thousands of small molecular weight (< 1000Da) biomolecules.
Amino acids, monosaccharide and disaccharide sugars, fatty acids, glycerol, nucleotides, nucleosides and nitrogen bases are some of the organic compounds present in living organisms.
There are 21 types of amino acids and 5 types of nucleotides.
Fats and oils are glycerides in which fatty acids are esterified to glycerol.
Phospholipids contain, in addition, a phosphorylated nitrogenous compound.
They are found in cell membrane.
Lecithin is one example of a phospholipid.
Living organisms have a number of carbon compounds in which heterocyclic rings can be found.
Some of these are nitrogenous bases -Adenine, guanine, cytosine, uracil and thymine.
When found attached to a sugar, they are called nucleosides.
If a phosphate group is also found esterified to the sugar they are called nucleotides.
Adenosine, guanosine, thymidine, uridine and cytidine are nucleosides.
Adenylic acid, thymidylic acid, guanylic acid, uridylic acid and cytidylic acid are nucleotides.
Only three types of macromolecules, i.e., proteins, nucleic acids and polysaccharides are found in living systems.
Lipids, because of their association with membranes separate in the macromolecular fraction. Biomacromolecules are polymers.
They are made of building blocks which are different.
Proteins are heteropolymers made of amino acids. Nucleic acids (RNA and DNA) are composed of nucleotides.
Biomacromolecules have a hierarchy of structures primary, secondary, tertiary and quaternary.
Nucleic acids serve as genetic material.
Polysaccharides are components of cell wall in plants, fungi and also of the exoskeleton of arthropods.
They also are storageforms of energy (e.g., starch and glycogen).
Proteins serve a variety of cellular functions.
Many of them are enzymes, some are antibodies, some are receptors, some are hormones and some others are structural proteins.
Collagen is the most abundant protein in animal world and Ribulose bisphosphate Carboxylase-Oxygenase (RuBisCO) is the most abundant protein in the whole of the biosphere.
Enzymes are proteins which catalyse biochemical reactions in the cells.
Ribozymes are nucleic acids with catalytic power.
Proteinaceous enzymes exhibit substrate specificity, require optimum temperature and pH for maximal activity.
They are denatured at high temperatures.
Enzymes lower activation energy of reactions and enhance the rate of the reactions greatly.
Nucleic acids carry hereditary information and are passed on from parental generation to progeny.
In some cases non-protein constituents called cofactors are bound to the enzyme to make the enzyme catalytically active.
In these instances, the protein portion of the enzymes is called the apoenzyme.
Three kinds of cofactors may be identified; prosthetic groups, coenzymes and metal ions.
Prosthetic groups are organic compounds and are distinguished from other cofactors in that they are tightly bound to the apoenzyme.
For examples, in peroxidase and catalase, which catalyse the breakdown of hydrogen peroxide to water and oxygen, haem is the prosthetic group and it is a part of the active site of the enzyme.
Co-enzymes are also organic compounds but their association with apoenzyme is only transient, usually occurring during the course of catalysis.
NAD, NADP are co-enzymes and contain niacin vitamin.
A number of enzymes require metal ions for their activity which form coordination bonds with side chains at the active site e.g. zinc is a cofactor for the proteolytic enzyme carboxypeptidase.
Enzymes
Enzymes
Proteins make up almost all enzymes. Some nucleic acids have enzyme-like properties. Ribozymes are the name for these proteins. A line diagram can be used to represent an enzyme. An enzyme, like any other protein, has a primary structure, which is the amino acid sequence. Secondary and tertiary structures are present in enzymes, as they are in other proteins. When you look at a tertiary structure, you'll observe that the protein chain's backbone folds in on itself, the chain crisscrosses itself, and many crevices or pockets form. The 'active site' is one such pocket. An enzyme's active site is a crevice or pocket that the substrate fits into. As a result, enzymes catalyze processes at a rapid pace through their active site.
In many aspects, enzyme catalysts differ from inorganic catalysts, but one key distinction stands out. At high temperatures and pressures, inorganic catalysts perform efficiently, but enzymes are destroyed at high temperatures (say, above 40°C). Enzymes extracted from organisms that dwell in severe heat (e.g., hot vents and sulphur springs) are stable and keep their catalytic power even at extreme temperatures (up to 80°-90°C). The capacity of such enzymes extracted from thermophilic organisms to maintain their thermal stability is thus critical.
Chemical reactions
Chemical compounds go through two sorts of transformations. A physical change is merely a change in shape that does not involve the breaking of connections.This is a bodily function. A change in state of matter is another physical process, such as when ice melts into water or when water becomes vapour. These are physical processes as well. A chemical reaction, on the other hand, occurs when bonds are broken and new bonds are generated during transformation. For example
Ba (OH)2+ H2SO4 ® BaSO4 + 2H2O
is a chemical process that takes place in an inorganic state. The conversion of starch to glucose is also an organic chemical reaction. The amount of product created per unit time is referred to as the rate of a physical or chemical process. It can be written as:
rate=dP/ dT
If the direction is indicated, rate is also known as velocity. Temperature, among other things, affects the rates of physical and chemical processes. For every 10°C change in either direction, the rate doubles or declines by half, according to a common rule of thumb. Catalyzed reactions proceed at a much faster rate than uncatalyzed reactions. For every 10°C change in either direction, the rate of enzyme catalysed reactions would be substantially larger than the same but uncatalyzed reaction. Catalyzed reactions proceed at a much faster rate than uncatalyzed reactions. When enzyme-catalyzed reactions are detected, the rate is much higher than when the identical process is not catalysed. As an example,
In the absence of any enzyme, this reaction is extremely sluggish, producing just around 200 molecules of H2CO3 per hour. The reaction speeds up substantially when carbonic anhydrase, an enzyme found in the cytoplasm, is used, with roughly 600,000 molecules generated every second. The enzyme has sped up the reaction rate by a factor of ten million. The power of enzymes is very amazing! Thousands of different enzymes exist, each catalysing a different chemical or metabolic reaction. A metabolic route is a multistep chemical reaction in which each step is catalysed by the same enzyme complex or separate enzymes. As an example,
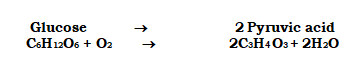
is a metabolic pathway in which glucose is converted to pyruvic acid via 10 enzyme-catalyzed chemical events. At this point, you should be aware that this metabolic pathway, when supplemented with one or two additional processes, produces a wide range of metabolic end products. Lactic acid is produced in skeletal muscle under anaerobic circumstances. Pyruvic acid is generated under typical aerobic circumstances. The similar route leads to the generation of ethanol in yeast during fermentation (alcohol). As a result, different products are possible depending on the circumstances.
How do Enzymes bring about such High Rates of Chemical Conversions?
The concept of an active site is already known. A reaction is referred to as a chemical or metabolic change. A'substrate' is the chemical that is transformed into a product. As a result, enzymes, which are three-dimensional proteins with a 'active site,' convert a substrate (S) into a product (P). This can be represented symbolically as
![]()
Within a specific cleft or pocket, the substrate 'S' must bind the enzyme at its'active site.' The substrate must diffuse into the 'active site.' As a result, the creation of a 'ES' complex is required. The letter E stands for enzyme. This intricate structure is a one-time occurrence. A new structure of the substrate called the transition state structure is created when the substrate is attached to the enzyme active site. The product is quickly removed from the active site after the intended bond breaking/making is completed. In other words, the substrate's structure is changed into the product's structure (s). This transformation must pass via a structure known as a transition state structure.Between the stable substrate and the result, there could be many additional 'altered structural states.' The notion that all other intermediate structural states are unstable is implicit in this assertion. Stability has to do with the molecule's or structure's energy status.
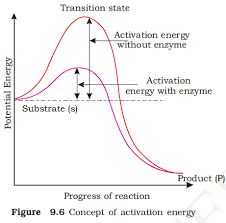
The potential energy content is shown by the y-axis. The x-axis depicts the structural transformation or states as they proceed through the 'transition stage.' There would be two things that you would notice. The difference in energy levels between S and P. When 'P' is less than 'S,' the reaction is exothermic. It is not necessary to provide energy (through heating) in order to manufacture the product. Regardless of whether the reaction is exothermic or spontaneous or endothermic or energy-demanding, the 'S' must pass through a significantly higher energy level or transition state. 'Activation energy' is the difference between the average energy content of 'S' and that of this transition state. Enzymes gradually break down this energy barrier, allowing the 'S' to become 'P' more easily.
Nature of Enzyme Action
In order to create a highly reactive enzyme-substrate complex (ES), each enzyme (E) has a substrate (S) binding site in its molecule. This complex has a brief half-life and dissociates into its product(s) P and the unmodified enzyme, with the enzyme-product complex forming in the middle (EP). Catalysis requires the creation of the ES complex.
E+S → ES → EP → E+P
An enzyme's catalytic cycle can be broken down into the following steps:
1. The substrate first binds to the enzyme's active site, fitting into the active site.
2. The enzyme's shape changes as a result of the substrate's binding, causing it to fit more tightly around the substrate.
3. The enzyme's active site, which is now in close proximity to the substrate, breaks the substrate's chemical bonds, forming a new enzyme-product complex.
4. The reaction products are released by the enzyme, and the free enzyme is ready to bind to another molecule of the substrate and repeat the catalytic cycle.
Factors Affecting Enzyme Activity
A change in the circumstances can impact the activity of an enzyme by altering the protein's tertiary structure. Temperature, pH, changes in substrate concentration, and the binding of certain molecules that affect its activity are examples of these.
Temperature and pH: Enzymes typically operate within a narrow temperature and pH range. The optimum temperature and pH for each enzyme are defined as the temperature and pH at which the enzyme is most active. Both below and above the ideal value, activity decreases. Because proteins are denatured by heat, low temperatures maintain the enzyme in a temporarily inactive state, but high temperatures eliminate enzymatic function.
Substrate Concentration: At first, the enzymatic reaction's velocity increases as the substrate concentration rises. The reaction eventually achieves a maximum velocity (Vmax) that isn't exceeded by any further increase in substrate concentration. This is because there are fewer enzyme molecules than substrate molecules, and there are no free enzyme molecules to interact with the additional substrate molecules after these molecules have been saturated. An enzyme's activity is also affected by the presence of certain molecules that bind to it. The process of inhibition occurs when a chemical binds to an enzyme, and the chemical is referred to as an inhibitor.Competitive inhibitors are those that have a chemical structure that closely mimics that of the substrate and inhibits the enzyme's activity. Because of its structural similarity to the substrate, the inhibitor competes with it for the enzyme's substrate binding site. As a result, the substrate is unable to attach, and the enzyme's activity is reduced, as seen in the inhibition of succinic dehydrogenase by malonate, which is structurally similar to the substrate succinate. Competitive inhibitors like these are frequently employed to combat bacterial infections.
Classification and Nomenclature of Enzymes
There have been thousands of enzymes identified, isolated, and analyzed. The majority of these enzymes have been divided into groups depending on the kind of reactions that they catalyze. Enzymes are classified into six classes, each having four to thirteen subclasses, and given a four-digit number.
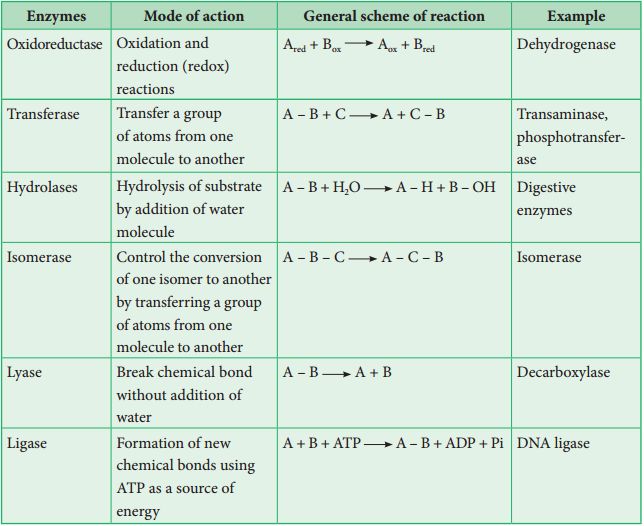
Co-factors
Enzymes are polypeptide chains made up of one or more polypeptide chains. However, in other situations, non-protein elements known as cofactors are coupled to the enzyme in order for it to be catalytically active. The apoenzyme refers to the protein part of the enzyme in these cases. Prosthetic groups, co-enzymes, and metal ions are all examples of cofactors. Prosthetic groups are chemical molecules that are strongly attached to the apoenzyme, distinguishing them from other cofactors. The prosthetic group haem is a component of the active site of enzymes like peroxidase and catalase, which catalyze the breakdown of hydrogen peroxide to water and oxygen.Co-enzymes are organic substances as well, although their relationship with the apoenzyme is very temporary, occurring most often during catalysis. Co-enzymes are also used as co-factors in a variety of enzyme-catalyzed processes. Many coenzymes contain vitamins as important chemical components; for example, the coenzymes nicotinamide adenine dinucleotide (NAD) and NADP contain the vitamin niacin. Metal ions that create coordination bonds with side chains in the active site while also forming one or more coordination bonds with the substrate are required for the activity of a number of enzymes, for example, zinc is a cofactor for the proteolytic enzyme carboxypeptidase. When a co-factor is removed from an enzyme, its catalytic activity is lost, indicating that they play an important part in the enzyme's catalytic activity.
